Guava Cache是在記憶體中快取資料,相比較於資料庫或redis儲存,訪問記憶體中的資料會更加高效

第二節 定址方式(重點)一、指令定址(由PC指出)Ⅰ、順序定址PC+”1“,這裡的1指指令字長,每次取值結束後PC會+1Ⅱ、跳躍定址執行轉移類指令導致的PC值改變二、資料定址(由本條指令的地址碼指明真實地址)非偏移指令定址方式有效地址優點缺

快取記憶體之所以能提升系統的速度是基於一種統計規律,主機板上的控制系統會自動統計記憶體中哪些資料會被頻繁的使用,就把這些資料存在快取記憶體中,CPU 要訪問這些資料時,就會先到 Cache 中去找,從而提升整體的執行速度

這就是為什麼我們寫System
一、電腦頻繁宕機,在進行CMOS設定時也會出現宕機現象,一般由硬體問題引起的,散熱不良,電腦內灰塵過多,cpu設定超頻,硬體存在壞道,記憶體條鬆動等
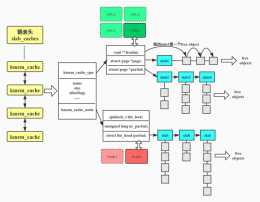
kmem_cache_allocslab_allocslab_alloc_node__slab_alloc //分配過程關閉了本地中斷___slab

if(interrupted)break
但是注意這只是針對單核,現在的處理器核越來越多,這下意義就大了,現在Intel處理器L3都是all cores的,就算一個核還有5%的資料L1,L2未中,4核8執行緒或者8核16執行緒也不少了
cache_method:選擇連線快取的方式cache_dir:指定快取的存放目錄關於 cache_dir 如無特殊需要,可以不用管,用預設的目錄即可/Users/iswbm/Library/Caches/pdm比較難以理解的,值得一講的是
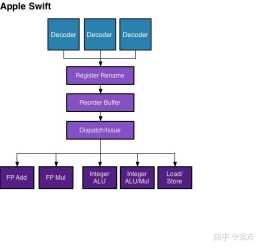
A6:SwiftA7:CycloneA8:TyphoonA9:TwisterA10:Hurricane/ZephyrA11:Monsoon/MistralA12:Vortex/TempestSwift是第一代蘋果自研架構,是一個三發射的亂序
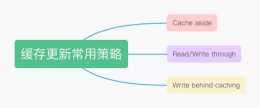
踩坑二:先刪快取,再更新資料庫如果寫請求的處理流程是先刪快取再更新資料庫,在一個讀請求和一個寫請求併發場景下可能會出現資料不一致情況

訪問Cache時,雖然不會對無效資料路進行訪問,但還是會對兩路的Tag進行比較,判斷路預測是否正確,當預測失敗時,需要重新發送該PC,使用正確的命中資訊重新訪問Icache讀取指令包,因此在路預測失敗時會影響取指的效能,需要花更多的代價進行

splice(index, 1)}}}keep-alive原始碼路徑在keep-alive快取超過max時,使用的快取淘汰演算法就是 LRU 演算法,它在實現的過程中用到了cache物件用於儲存快取的元件例項及key值,keys陣列用於儲存

++i){for(intj=weight[i]
那麼資料從記憶體載入到 CPU Cache 裡面的時候,不是一個一個數組元素載入的,而是一次性載入固定長度的一個快取行
對於這一問題,在cluster內使用快取一致性邏輯(cache coherency logic)用於保證cluster內多個cache的資料一致性,而多個cluster之間使用到big-LITTLE架構就要用到cache coherent
這些最佳化選項基本可以分為三大類:調整資料的訪問順序一般是由於迴圈結構,導致有多個數據(如陣列,連續分佈)在一個很短的時間內都想去佔有cache
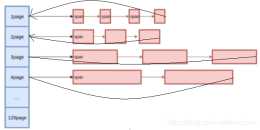
Central Cache申請記憶體:當thread cache中沒有記憶體時,就會批次向Central cache申請一定數量的記憶體物件,Central cache也是一個雜湊對映的Spanlist,Spanlist中掛著span,從s
資料庫儲存大量資料時操作緩慢,有什麼好辦法提高速度