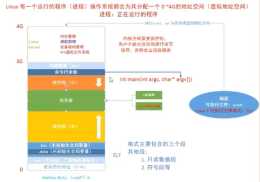
記憶體訪問級別的設定和修改(記憶體保護),在完成對映的同時,會設定CPU訪問該段記憶體的訪問級別(3,2,1,0 Linux只有使用者空間3,核心空間0),如圖:ro表示read only0和3表示訪問級別程式運行了兩次,產生兩個獨立的程序

而當程序訪問的虛擬地址在頁表中查不到時,系統會產生一個缺頁異常,進入核心空間分配物理記憶體、更新程序頁表,最後再返回使用者空間,恢復程序的執行

// level=0,向右移出12位,經掩碼後得到9位level=0頁表的PTE編號// 返回va對應的level=0頁表中的對應PTE}值得注意的細節是,在頁表未被啟用,核心利用以上函式初始化核心頁表時,能夠正常工作,是建立在核心虛擬地址

例如:在Python的記憶體管理機制上面,即用到了“大物件記憶體直接alloc, 小物件使用記憶體池分級進行管理”是一種比較複雜的記憶體管理機制在Nginx中也使用了記憶體池的概念,即Nginx對每個TCP連線都分配了一個記憶體池,HTTP
對於這一問題,在cluster內使用快取一致性邏輯(cache coherency logic)用於保證cluster內多個cache的資料一致性,而多個cluster之間使用到big-LITTLE架構就要用到cache coherent
啟用大量程序造成記憶體緊張不足的時候,作業系統會透過記憶體交換技術,把不常使用的記憶體載入到硬碟(換出),使用時從硬碟載入到記憶體(換入)作業系統對記憶體的管理方式分為三種,分段、分頁、段頁,分段的好處是物理記憶體空間是連續的,但是缺點很明

相比之下,每當發生程序切換時,地址空間的使用者模式部分的對映就會發生變化:藍色區域表示對映到物理記憶體的虛擬地址,而白色區域表示未對映
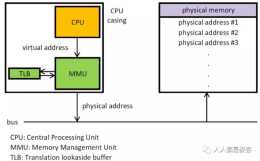
現在我們假設每一頁的大小是 4KB,而且頁表只有一級,那麼頁表長成下面這個樣子(頁表的每一行是32個 bit,前20 bit 表示頁號 p,後面12 bit 表示頁偏移 d):CPU,虛擬地址,頁表和物理地址的關係如下圖:頁表包含每頁所在物
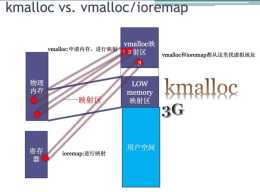
vmalloc:申請記憶體,申請到就拿到記憶體,並且已經修改了程序頁表的虛擬地址到物理地址的對映
接下來配全圖片,以一個例子說明頁與頁框之間在MMU 的排程下是如何進行對映的:在這個例子中,我們有一個可以生成16位地址的機器,它的虛擬地址範圍從0x0000 ~ 0xFFFF(64k),而這臺機器只有32K 的物理地址,因此它可以執行64
簡化記憶體分配:在使用malloc等記憶體分配函式時,由於頁表的存在,作業系統沒必要分配連續的物理頁面給程序,而是在程序自己的虛擬地址空間找一塊連續的虛擬地址分配給程序,當實際訪問這塊新分配的虛擬地址時,缺頁相關程式碼會將其對映到實際的物理
一級頁表:物理記憶體中一共有1048576個頁,那麼頁表就需要總共就是1048576 * 4B = 4M

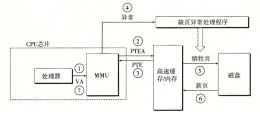
3 翻譯加速從頁命中的流程圖中可以看出,CPU 每次需要請求一個虛擬地址,MMU 就需要從記憶體/快取記憶體中獲取 PTE ,然後再根據 PTE 的內容去從物理記憶體中載入資料
參考:《Linux 核心設計與實現》程序的頁面只有在物理記憶體將要耗盡的時候才會被pageout出去,否則就在物理記憶體,運氣好還能進cache呢頁表是開機階段創立的,後續的只是對頁表的分配
s檔案中,每個符號定義都沒有明確的執行時地址(虛擬地址),然而操作變數或者呼叫函式之類的符號引用,都是需要一個明確的地址的(暫存器變數除外),所以就需要為這些符號分配一個執行時的虛擬地址,這就由連結中的重定位來完成最後生成的檔案也是由二進位
這是ARM32才有的高階和低端記憶體,這是為了解決虛擬地址不夠的問題你的問題跟ARM64下 4G記憶體都有線性對映一樣,核心只是映射了地址,並沒有使用,使用者態申請到虛擬地址後 在寫時發生缺頁異常,才分配到真實物理地址,並建立使用者態的對映

因此係統將程序1的虛擬記憶體對映到相同記憶體之中,完成檔案的共享
這些功能是軟硬體聯合提供的,包括作業系統、MMU(記憶體管理單元)中的地址翻譯硬體和一個存放在物理記憶體中叫作頁表(page table)的資料結構,頁表將虛擬頁對映到物理頁面
搬移後如果程式訪問該虛擬地址,那處理器會產生一個記憶體違例異常,程式的控制權進入作業系統,作業系統對地址做安全檢查,發現是程式的合法地址,再一查發現是被交換到磁碟了,於時將磁碟的內容讀出來,放到記憶體上,再修改頁表設定成“頁可用”的狀態