CPU終章(3)
當我們專注地研究人類生活的空虛,並考慮榮華富貴空幻無常時,也許我們正在阿諛逢迎自己懶惰的天性
— —
休謨
目錄:
九、Cache如何保證資料一致性?
十、虛擬地址
十一、多核處理
九、 Cache如何保證資料一致性?
從軟體來看,兩個core之間要保證資料一致性,可以讓cache把資料寫進memory,而另一個core從memory讀取資料就好了。從硬體來看,就要複雜一點,同一個cluster中需要
快取一致性邏輯(cache coherency logic)
,不同cluster間則需要
ACE,CHI匯流排
來保證一致性。
在ARM Cortex-A8的處理器之前,只有一個核,不用考慮cache資料一致性的問題,而多個核(
MPcores
)就需要考慮這一問題了。譬如說,兩個core的L1 cache都對應到外存中的同一地址,那麼當他們向各自cache的這一地址寫資料時,各cache中對應到外存的值不一樣了,即dirty,誰最後寫進外存決定了外存中的值是哪一個,這樣它們之間就產生了
競爭
關係。
對於這一問題,在cluster內使用快取一致性邏輯(cache coherency logic)用於保證cluster內多個cache的資料一致性,而多個cluster之間使用到big-LITTLE架構就要用到
cache coherent interconnect, SCU(Snoop Control Unit)
,這需要ACE以上的匯流排的snoop功能使cache之間相互查詢,來保證各cluster之間的資料一致性。在big-LITTLE中,使用CCI互聯匯流排(基於ACE bus)或CCN互聯匯流排(基於CHI bus)來保證多個大小核和裝置之間的互聯。
MOESI或MESI protocol
,這是在L1 data cache的tag中額外擴充套件的cache狀態標誌位。其中
M意謂Modified,表示data dirty,O意謂Owned,表示多個cache share了這個地址,並且資料是dirty,E意謂Exclusive,表示只有這一cache有這一地址,資料是clean,S意謂Share,表示多個cache share了這個地址,並且資料是clean。I意謂Invalid,表示資料不是有效資料
,因為可能查詢到別個cache中已經修改了這一地址的值,因此把自己的cache line invalid掉。
而一致性邏輯是如何保證多個core之間的資料一致性呢?
在cache coherency logic中,會把各個core的Tag複製一份,當某個core想從memory中讀取資料時,coherency logic會先和各個core的tag比較一下,如果有,就從另一個core的cache中拿,這樣就不用訪問外存,節省時間,如果沒有,再從外存中讀取資料。
當某個core執行寫操作時,它會發出snoop指令給其他core,其他core查詢自己的cache是否有這一地址,有的話就invalid掉,因為發snoop的那個core準備要寫資料,寫之後自己cache中的值肯定就不正確了。Invalid掉後回resp給發起snoop的core,該core再執行寫操作
。
在訪問共享資源時,為了防止多個master同時訪問同一片資源,造成資料混亂,可以使用
exclusive或lock
這樣的原子操作,這樣在編譯成彙編指令時,只會按照順序執行,不會穿插其他指令。Lock指令其他master都不能訪問,對效能有很大影響,應少使用。Exclusive是透過monitor記錄要訪問的地址中的資料,向地址中寫一個數據時,monitor比較這一地址的資料是否有改變,沒有就回exokay,表示寫成功,否則回okay表示寫失敗。這樣別的master還是能訪問其他地址,對效能影響較低。另外外設一般是uncache的,因為訪問外設時,一般是希望能及時得到響應。
十、 虛擬地址
使用記憶體時,資料有可能分散儲存,這樣一些零碎的沒有使用的地址,就浪費了。為了節約面積和成本,使地址分配更靈活,把這些零碎的地址也可以組織起來使用,就用到了虛擬地址,虛擬地址和物理地址不用一一對應,對應的物理地址也可以是不連續的,但是軟體的人看來,虛擬地址是連續的,方便使用的。
在編譯時,編譯器分配好地址空間,在程式載入階段,把程式載入到固定的空間。當程式一旦執行起來,就沒辦法再修改地址空間了。物理空間可能有不連續的物理地址,這時可以用虛擬地址轉換,把不連續的物理地址轉化為連續的虛擬地址。虛擬地址和物理地址之間用Transiation Tables來mapping。
虛擬地址由
Virtual address(VA)和offset
來組成,
VA用來在Transiation table中查詢PA(physical address),PA再和offset組成新的物理地址
,這個物理地址就是實際物理記憶體的地址。顯然,
offset就是記憶體顆粒的大小
。
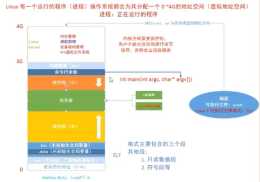
為了合理的使用面積,我們也可以配置物理記憶體空間大小,如圖1,比方說VA可以拆分為L0 index,L1 index,和L2 index,對應到Level1 transiation table和Level2 transiation table,當我們只啟用L1 transiation table時,L1 index就是虛擬地址作為物理地址的索引,
在L1 table中將虛擬地址轉化為物理地址
,此時L2 index+offset就是實際儲存顆粒大小,如下圖。這時,儲存空間大小為1G,如果統共有5個G大小,則有5個這樣的區域。如果在TTBR暫存器中找到下一級的索引,L1 index會在L1 table中索引到L2 table的地址,
然後在L2 table中將虛擬地址轉化為物理地址,這時,每個儲存空間大小為2M
,則劃分為了5G/2M這麼多個空間。使用幾級table,多大的儲存空間,應按照實際需求來決定。

圖1 多級transiation table
在多工處理中,在
處理器看來它一次只能執行一個任務,對應一個虛擬地址空間,但是對於硬體來說,需要分配多個物理地址空間來和任務一一對應
。但是物理記憶體的訪問,需要從TLB中索取物理地址,為了提高效能,TLB一般儲存於cache中,那每次切換任務,都需要cache從記憶體中讀取TLB,會降低效能。
這時可以透過
ASIDs
來解決這個問題,
將該任務VA tag,ID,Attributes放在ASIDs表格中,若執行任務的ID與context ID匹配,則TLB heat。為了更快得到TLB,TLB同樣也可分為data TLB,instruction TLB,再往下是main TLB,再從cache中查詢,當cache中也沒有想要的TLB時,再從外存中查詢。
TLB:translation look-aside buffer,存放最近一次的entry。
MMU: memory management unit,可以虛實轉換。
MPU: memory protection unit,簡單的記憶體控制單元。
一般而言,TLB和Table Walk Unit就在MMU中,可以跑複雜的作業系統。而對於一些嵌入式系統的應用,只是跑實時作業系統,這些作業系統都是物理地址,不需要虛實轉化,所以MPU就可以了。
當cache中資料出錯了,一般提供
Parity和ECC
兩種校驗機制,Parity可校驗1bit,兩位元就可能出錯。ECC校驗記錄7位元資訊,產生了1位元的錯誤可以校驗回來,2位元的錯誤可以檢測到。
十一、 多核處理。
ARMv6架構時,就可以跑多核了,多核造成了一些資料一致性的影響及處理前面也有講到。而在多核處理中,為了提高處理速度,對暫存器的操作也有不同。
SISD,SIMD,MISD,MIMD: sigle/multiple instruction/data。
一般對暫存器的操作是SISD,即一個指令操作一筆8bits資料,SIMD將操作暫存器分為4個vector,
一個指令可以操作4個共32bits資料,提高了效率。
而資料量大時,希望運算元更寬,這時可以使用
NEON指令(Advanced SIMD)。一個vector可對應32bits,4個vector即可以操作128bits的資料。
例如,一個for迴圈迴圈16次,常規需要迴圈16次處理完的資料,使用NEON指令只需要迴圈4次便可以處理完。
在多核系統中,CPU1要執行一些task0,而CPU2要執行一些task1,這時需要用到
非對稱多核處理架構(Asymmetric Multi-Processing)
,在這種架構中,CPU1和CPU2需要跑不同的任務,接不同的外設,不同的OS,不同的VA,不同的memory,但是SA是一樣的。
而在CPU都是同頻的
對稱多核系統(SMP)
中,可以跑一樣,也可以跑不同的任務,其他的外設也都是共享的,不過容易有資料一致性問題,所以CPU之間需要有一種握手協議,增加一個interrupt controller,並且同享一個L2 cache。
而要支援跑不同頻率的CPU,ARM用到了
big.LITTLE架構
,big和LITTLE的cluster各一個L2 cache,它們之間的資料一致性透過coherent interconnect來保證。
但是
coherent interconnect需要SCU(snoop control unit)
來保證資料一致性,終歸要多花些時間。後來ARM在不同頻的cluster下面又加了一級L3 cache,致力於提高不同頻cluster之間的通訊,這就是
DynamIQ big.LITTLE
架構,麒麟980就是基於這一架構的晶片。
而一個系統中的互聯(interconnect)也影響著系統的速度,因此常見的互聯有
共享,交叉,環狀,網狀互聯
應用於各種型別的系統中。
【猛男舞團】新寶島remix 宴 請 八 方【BML2019廣州單品】_嗶哩嗶哩 (゜-゜)つロ 乾杯~-bilibili