該晶系唯一的一個高次軸——四次軸(L4)相當於縱軸(Z 軸),另外兩竹目互重直的二次軸(L2)或對稱面的法線(若無 L2或 P,X、Y 軸平行晶稜選取)分別相當於 X 軸和 Y 軸

——《房山明咒集》L2
如此一來,大量L2類人會轉化為L3類人,我們如果認為我們的世界A中願意6000買票的人足夠多,那麼可以認為最後所有L2都會把票賣掉
跟它打配合的應該還有兩個單開雙控的開關,L1接火線,L11、L12接其中一個燈開關(開關A)的兩根並聯線(不分極),開關A應該是三個孔,其中兩個孔與L11、L12接了並聯線,另外一個孔接燈頭線
先說L0正則化:這玩意長這樣:0的0次方沒有意義,在這裡如果按照L1和L2看顯然該定位0,這裡討論就是不參與懲罰項,不參與加權

分析如下:殘差分佈比較:①當分量|u|≤1時,l1罰函式>>l2罰函式,此時損失函式的主要貢獻者是|u|,誰貢獻最多就最佳化誰,也就是l1罰函式相對於l2罰函式對<1的值懲罰權重比較大
但是注意這只是針對單核,現在的處理器核越來越多,這下意義就大了,現在Intel處理器L3都是all cores的,就算一個核還有5%的資料L1,L2未中,4核8執行緒或者8核16執行緒也不少了
如果再回到母語環境,那麼相對L1的熟練度就會增加,相對的,L2就會產生磨蝕現象,說白了就是我們說的“不用就忘了”
1、想法一維的情況,兩條線段[l1,r1][l2,r2]相重疊,必須滿足max(l1,l2),然後同理推廣到二維的矩形classSolution{public:boolisRectangleOverlap(vector<int>

例如,CTA 範圍同步中涉及的儲存(直觀地)不需要寫入 L2,但在時間一致性中,每個儲存都寫入 L2,因為它是在直寫/無寫入分配 L1 的假設下設計的 快取

在神經網路訓練的過程中,欠擬合主要表現為輸出結果的高偏差,而過擬合主要表現為輸出結果的高方差圖一為欠擬合,圖三為過擬合欠擬合欠擬合出現原因模型複雜度過低特徵量過少欠擬合的情況比較容易克服,常見解決方法有增加新特徵,可以考慮加入進特徵組合、高
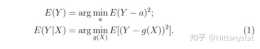
這說明,在迴歸擬閤中,應儘可能地收集和響應變數Y相關的自變數,以使得擬合誤差儘可能的小
謝邀首先,凱恩斯理論中的“貨幣需求”指的是三大需求,即:交易需求,與國民收入Y正相關預防需求,與國民收入Y正相關投機需求,與利率r負相關因此,我們有凱恩斯的貨幣需求公式:L = L1(Y)+L2(r)流動性陷阱,可以理解為在利率過低的時候,

整合式巡航輔助ICA(Integrated Cruise Assist):高速ACC和LKA功能的整合,也可以看作是TJA的全速域升級版,在車輛高速行駛時(60km/h以上),實時監測車輛前方及相鄰車道行駛環境,經駕駛員確認後,自動對車輛進
整體來說,都彭打火機比較受歡迎的主要是Ligne2產品線(包括L2整個大家族,無論外觀還是聲音都非常有辨識度)、Slim產品線(包括E-Slim,主打輕薄、便攜),如果考慮送人的話,建議還是在L2家族範圍內進行選擇
從而原命題等價於“過平面內一點有且僅有一條直線與平面垂直”
一.L1正則化和L2正則化L1正則化是指權值向量ww中各個元素的絕對值之和,通常表示為||w||1||w||1L2正則化是指權值向量ww中各個元素的平方和然後再求平方根(可以看到Ridge迴歸的L2正則化項有平方符號),通常表示為||w||

iloc[w,1]=l[i]result
這麼說吧,沒前途,每天工作重複,兩班倒

PSConv:將特徵金字塔壓縮到緊湊的多尺度卷積層中ECCV 2020 | STTN:用於影片修復的時空聯合TransformerECCV 2020 Oral | DG-Net++:面向跨域的行人重識別新網路ECCV 2020 | 北郵提出