
size的時候,則按照訊息預估記憶體建立, 否則按照batch
而deltas裡面的元素表示的啟用函式的輸入即的梯度,那麼權重矩陣和維度為的偏差矩陣的梯度可以表示為:(對應的定理是以及鏈式法則)、,對應的程式碼為(需要除以batch):layer = np

圖1 Res50-FPN使用學習率線性尺度原則在不同batch size訓練時的精度(LSR表示學習率線性尺度原則,half表示學習率變為原來的一半)為了解決大batch size訓練時網路發散的問題,LAMB演算法使用神經網路每一層的引數

因此,使用FP16時,總的訓練速度加速了2~3倍:Comparison of the training time and validation accuracy for ResNet-50 between the baseline (BS=
001 # 初始學習率burn_in=1000 #max_batches = 500200 # 訓練達到max_batches後停止學習policy=steps # 調整學習
init_hidden(batch_size)embed=self

DataLoader(val_set,batch_size=batch_size)model,criterion,optimizer,scheduler=initialize_model(learning_rate,input_size,h
matmul(out_aug,out_aug,transpose_b=True)/temperature#[batch_size,batch_size]logits_aa=logits_aa-masks*INF# remove the sa
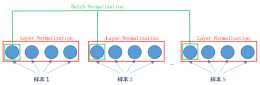
layer是“橫”著來的,對一個樣本,不同的神經元neuron間做歸一化
apply_gradients(zip(grads, tvars), global_step=global_step)#返回return ((img_feature, sentence, mask, keep_prob),(loss, ac

txt’)foriinrange(1000)]paths=batch(paths,128)time_cost=[]ts=time()fori,eleinenumerate(paths,1):# read(paths[i - 1])ray_r
split(‘_’)[3]text_list

這篇CVPR的工作是Facebook AI團隊何愷明等人的作品,提出了基於動量對比的自監督方法,這是一種同時將資料樣本的字典存在佇列中而不是之前和mini-batch耦合的方式,從而成功地將字典的大小和batch大小進行解耦,儘可能地增大了
pyplotaspltnum_epochs=100total_series_length=50000truncated_backprop_length=15state_size=4num_classes=2echo_step=3batch_
當然我們是可以用之前提到的對資料做 normalization 預處理,使得輸入的 x變化範圍不會太大,讓輸入值經過激勵函式的敏感部分
05,“ns”,if_else(abs(logFC) < 1, “ns”,if_else(logFC >= 1, “up”, “down”)))) %>%arrange(desc(abs(logFC)))dim(DE_re
alpha = alpha# 之前僅僅是`forward`,現在我們在前向傳播中基於合成梯度更新權重def forward_and_synthetic_update(self,input):# 快取輸入self
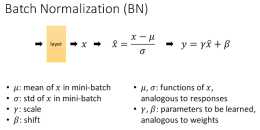
開始解釋Batch Normalization前先了解一個概念, Feature ScalingFeature Scaling如果特徵大小差的比較遠的話,loss function會很扁平,數值更大的feature的引數會對結果的影響更大,
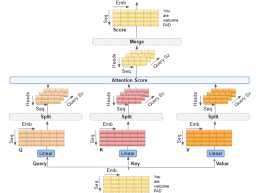
linear_q(x)# batch, n, dim_kk=self