
深度可分離卷積卷積要解釋深度可分離卷積,就要從卷積過程開始說起,我們假設輸入為N x H x W x C的特徵向量,其中N為特徵向量個數,H、W為特徵圖的長寬,C為特徵向量的通道數,當我們用k個卷積核進行卷積操作時,如果設定步長為1,那麼最

c.學習bbox regression迴歸利用卷積網路計算bbox位置修正資訊,detection面臨的一個問題是帶標記的資料少,當時可用的公開資料集不足以訓練大型CNN來計算bbox位置修正,paper中提出以VGG網路中引數為基礎,用P

圖七:The Architecture of FPN from AVOD然而,在encoder中經過下采樣後原影象的spatial information是逐層損失的,很多關於位置的細節資訊都被丟失掉(我們可以稱這些資訊為feature s
![[R]用limma分析晶片資料 1](https://img.heatask.com/upload/thumbnail/fiU511GvNc9qeMOW0q=v8WgvFHPT1U9Q1K4uOFNeZxNJ0ekKdZWRrDNgWU_KP0JKgWP2mhB+GncQdLBP1SkyDmD79hMe1uVfdQVHOUeamLUrgzujb.jpeg)
表格的左右拆分用的就是簡單暴力的列舉column name的形式,然後請注意,pheno往csv的輸出是不帶index的,而df_assay和df_feature是帶index的,這是因為我在拆分的時候兩個表沒有任何共同的列,如果你給兩個表

DOF Input 512 sppdenoised 512 sppInput 128sppDenoised 128spp缺點是performs worse than feature based filters in feature rele

advance(index*3,‘month’),ee
(想法挺好的)Loss Functions繼承DAG的標籤損失X is the extracted feature map from the feature network of Faster-RCNN on 影象I

所以deepmotion就提出了DenseASPP,將DenseNet中的密集連線思想應用到了ASPP中,其結構如下圖更直觀一點每一層空洞卷積層的輸入都是 前面所有卷積層的輸出和輸入的feature map的拼接空洞卷積的卷積核大小計算公
fea=fea_outdefget_feas_by_hook(model):“”“提取Conv2d後的feature,我們需要遍歷模型的module,然後找到Conv2d,把hook函式註冊到這個module上
apply_gradients(zip(grads, tvars), global_step=global_step)#返回return ((img_feature, sentence, mask, keep_prob),(loss, ac

因此,我們可以透過計算feature cluster 的方式來查閱其距離,在這裡我們使用 hierarchy 結構,但是你要記得你的模型可能是經過 fillna 的,這個部分是否會影響模型特徵相似性的分析,需要單獨個案的討論,當然也是會被

_keras_shape[channel_axis]shared_layer_one=Dense(channel//ratio,activation=‘relu’,kernel_initializer=‘he_normal’,use_bia

卷積層計算量 = 卷積矩陣操作 + 融合操作 + 偏置項操作注意:其中矩陣操作包括:先乘法,再加法若有一張通道為,大小為的圖片,卷積核大小為:,為為輸出通道數為,其輸出feature map的大小為,feature map中的每一個畫素點,
具體到視覺關係中,文章強調,用於簡單判別predicate的特徵應當是與具體影象無關的(image-agnostic),然後定義了兩種可用的特徵:categorical feature和spatial feature,前者透過one-hot
initialization過程:首先initialStructure(),也就是採用SFM估算sliding window中的兩個關鍵幀的pose並初步triangulate一些feature,再採用PnP得到所有幀的pose,對應論文中

能看出來經過零上取樣和 warp 之後會有明顯的摩爾紋,之後利用了神經網路去修復,讓它還原了演算法流程:特徵重加權網路該步驟是為了消除鬼影等問題,即對每一個過去幀計算一個權重再帶權累加

但是其中有一些思想(3D如何使用2D影象特徵)是值得一定程度借鑑的,不過與此同時,仔細研讀分析之後,作者目前的使用方式也的確會存在很大的問題
將一般去噪網路建模為:feat=encoder(noisy rgb),noise = decoder(feat) ①clean rgb = decoder(feat) ②從encoder角度看,對於不同的場景影象,①編碼類似的噪聲分

sum(dim=(2,3))+1e-5)returnmasked_feature實驗結果在 PASCAL-5 資料集上的實驗結果:unlabeled 表示最後提出的那個輔助任務,使用額外的未標註圖片來幫助訓練在 COCO-20 資料集上的實
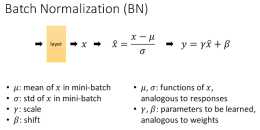
開始解釋Batch Normalization前先了解一個概念, Feature ScalingFeature Scaling如果特徵大小差的比較遠的話,loss function會很扁平,數值更大的feature的引數會對結果的影響更大,