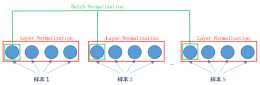
layer是“橫”著來的,對一個樣本,不同的神經元neuron間做歸一化
當然我們是可以用之前提到的對資料做 normalization 預處理,使得輸入的 x變化範圍不會太大,讓輸入值經過激勵函式的敏感部分
開始解釋Batch Normalization前先了解一個概念, Feature ScalingFeature Scaling如果特徵大小差的比較遠的話,loss function會很扁平,數值更大的feature的引數會對結果的影響更大,

上面的均值和方差會被記住,然後測試的時候,就使用記住的均值和方差,而不再透過輸入計算(因為輸入可能只有一張而非batch,並且希望對於所有輸入同等對待而不因為不同的輸入而有不同的結果)Inception v2然後作者在Inception的基
作者提出不同通道的statistics discrepancy不同,需要給不同的通道分配不同重要性:其中,最後可遷移的規範化可表示如下:ExperimentsTransNorm 在 Office-31, ImageCLEF-DA 以及 Of
另一方面,一旦在mini-batch梯度下降訓練的時候,每批訓練資料的分佈不相同,那麼網路就要在每次迭代的時候去學習以適應不同的分佈,這樣將會大大降低網路的訓練速度,這也正是為什麼我們需要對所有訓練資料做一個Normalization預處理

03167v3,第5頁)We add the BN transform immediatelybeforethe nonlinearity(注意:before的黑體是我加的,為了突出重點)但是,François Chollet爆料說BN論文

相關工作:模型剪枝預蒸餾(Model Pruning and Distill):網路的剪枝就是減少網路結構,包括通道數,卷積核與網路深度

摘要作者在不同任務中嘗試了節點式歸一化(Node-wise),鄰接式歸一化(Adjance-wise),圖式歸一化(Graph-wise)和批處理歸一化(Batch-wise)作為歸一化計算方式,來分析每種歸一化方式的優劣,並提出一種基於學
至於為什麼需要 layer normalization,我的理解是為了應對有時一個向量裡的元素值太大或者太小

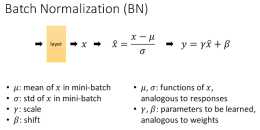
谷歌在2015年就提出了Batch Normalization(BN),該方法對每個mini-batch都進行normalize,下圖是BN的計算方式,會把mini-batch中的資料正規化到均值為0,標準差為1,同時還引入了兩個可以學的參
bn在訓練時,透過對每一個mini-batch的資料做一個規範化的操作,強行把其分佈變成以0為均值,1為方差的分佈(為什麼要變成這樣一個分佈,可以參考影象裡面的白化操作),這樣絕大部分的資料會落在以0為中心的附近,從而可以較少梯度消失的影響
![[知識點] “歸一化、標準化”的概念混淆解析、計算公式、作用、注意事項](https://img.heatask.com/upload/thumbnail/oUMCDwRPRngKluj6TPhhvtS1TFTXu0-Vt8UzSfq4t5aW7pG6-n1kIt0=o+k7fspenL+X6VvXSGdF7xhU-8JW_wOflXvnuXtp7k0lS0los5M6n-FYo.jpeg)
分情況來討論:- 當對模型採取正則化的時候,標準化是必須的,因為正則化關注的是引數,如果不對特徵進行標準化,則正則項偏向於關注數值範圍大引數(對應的特徵一般數值範圍偏小)- 當不採取正則化的時候,標準化不是必須的,但是如果採取標準化,則引數

不過,除了直接用這種方式的初始化外,我們還可以有另外一種引數化的方式:用“均值為0、方差為1的隨機分佈”來初始化,但是將輸出結果除以,即模型變為:這在高斯過程中被稱為“NTK引數化”,可以參考的論文有《Neural Tangent Kern