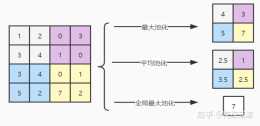
c) 全域性最大(平均)池化是計算整個特徵圖內的最大值(平均值)

深度卷積Depthwise Convolution的大概意思是特徵圖的一個通道對應一個卷積核進行計算所以深度卷積不改變影象的通道數量,但是並沒有有效的利用不同通道在相同空間位置上的feature資訊

整圖經過CNN,得到特徵圖經過核為 3×3×256 的卷積,每個點上預測k個anchor box是否是物體,並微調anchor box的位置提取出物體框後,採用Fast RCNN同樣的方式,進行分類選框與分類共用一個CNN網路anchor

2 Local Importance-based Pooling作者提出了一種新的pooling方式,如圖所示:具體思路是,在原feature map上學習一個類似於attention的map,然後和原圖進行加權求平均,公式表述如下:需要說
2.貢獻(Contribution)新提出的Fast R-CNN模型解決了之前模型存在的問題,並使得模型具有以下的優點:目標檢測的效能(mAP)要高於R-CNN和SPPnet整個訓練過程是single-stage的,並且使用了multi-t

最近一直再更新transformer系列的文章,如果你還沒有了解到,請先關注我獲取更多更新,同時歷史的文章可以看這裡:萬字長文盤點2021年paper大熱的Transformer(ViT)金天:萬字長文盤點2021年paper大熱的Tran
可以看到:所提方法在不增加引數量的同時具有更高的效能,優於SE、GE等常用模組
其實這是一個問題,就是什麼情況下可以使用CNN:卷積物件有區域性相關性,如一張圖片中左半邊是貓,而右半邊存在與否都沒關係了
作者提出了分割中常見的兩個問題:(1)同個物體可能存在不同的size導致了分類的困難(對於存在多種物體,輪廓是正確的但是分類錯誤,即把貓圈出來但是認為是狗),而PSPnet和Deeplab系列都是使用ASPP的結構來試圖解決這個問題,而認為

PointNet系列(3)-Frustum-PointNet論文解讀主要介紹了純點雲作為輸入的模型結構, 這篇文章介紹一種另外一種思路, 將點雲投影到2維柵格(這裡是鳥瞰圖 Bird‘s eye view)之後再做識別的方法
這是2017年NIPS上的一篇做動作識別的論文,作者提出了second-order pooling的低秩近似attentional pooling,用來代替CNN網路結構中最後pooling層常用的mean pooling或者max poo

2.2 Graph PoolingPooling layer讓CNN結構能夠減少引數的數量【只需要卷積核內的引數】,從而避免了過擬合,為了使用CNNs,學習GNN中的pool操作是很有必要的,Graph pool的方法主要為三種:topol

在影象分割領域,影象輸入到FCN中,FCN像傳統的CNN那樣對影象做卷積再pooling,降低影象尺寸的同時增大感受野,但是由於影象分割預測是pixel-wise的輸出,所以要將pooling後較小的影象尺寸upsampling到原始的影象

現在不是有了sppnet和roi pooling的框架,把上面的這個在原圖中進行窮舉滑動的操作,換到了比原圖小很多的特徵空間(比如224*224 --> 13*13),還是搞滑動視窗,就得到了rpn,如下圖

The network architecture of FCOS結果FoveaBox: Beyond Anchor-based Object Detector主要思想:直接學習目標存在的機率和目標框的座標位置,其中包括預測類別相關的語義圖和
因為feature map本身就具有冗餘,我們需要去掉這些冗餘的資訊,在做pooling時,如果使用average pooling,還是把這些冗餘的資訊考慮進來了,不如直接用max pooling,選取最顯眼的那一個特徵,當然這也有可能會有