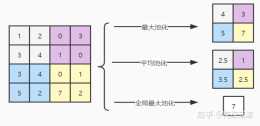
c) 全域性最大(平均)池化是計算整個特徵圖內的最大值(平均值)

深度卷積Depthwise Convolution的大概意思是特徵圖的一個通道對應一個卷積核進行計算所以深度卷積不改變影象的通道數量,但是並沒有有效的利用不同通道在相同空間位置上的feature資訊

SPP-Net與R-CNN的流程對比如下圖所示:一個3x3的空間金字塔結構配置如下:所以,我們總結一下SPP-Net的基本思路:把整張待檢測的圖片,輸入CNN中,進行一次性特徵提取,得到feature maps,然後在feature map

輸出神經元個數等於輸入神經元個數除以步長(向上取整)ceil(13/5)=37 使用zero padding相關計算一:(“same”模式下)(1)原始圖片的高,寬可以被步長整除Eg:輸入圖片為6*6,卷積核大小為3*3,步長為(1,2)那

如何看待計算機視覺未來的走向使用Dice loss實現清晰的邊界檢測CNN結構演變總結(一)經典模型CNN結構演變總結(二)輕量化模型CNN結構演變總結(三)設計原則CNN視覺化技術總結(一)——特徵圖視覺化CNN視覺化技術總結(二)——卷

至於隱藏層如何提取特徵,取決於我們這個神經網路的作用(不同的神經網路提取特徵的方式不一樣),比如CNN就是在透過卷積操作提取影象特徵,而輸出層本身在接受最終的特徵資料進行分類

之後採用記憶庫特徵的平均作為目標核與每張提取的特徵圖做 depth-wise 卷積操作,得到互相關圖:這個互相圖經過一個層標準化 LN,和一個密度迴歸網路得到最終預測圖,公式為:之後訓練採用 Bayesian Loss 作為損失函式,啊啊啊
論文的實驗部分證明,GeM池化優於傳統的平均池化和最大池化,學習單個P優於學習多通道各自的Pk,孿生網路和損失函式Siamese孿生網路是圖片檢索的常用方法,文中構造了一個二分枝網路,分枝使用相同構造方法並共享引數,兩分枝分別提取需要對比的

作者通過幾個實驗進行了比較,說明其富有效果利用imagenet的分類任務說明,在不同的backbone結構下,加入CBAM都有提升利用梯度視覺化方法,繪製attention輸出的結果與原來輸出結果的熱圖,分析生成的區域是否可行,並且,利用網
因此在文章中作者使用膨脹卷積來解決這個問題,使用KD代替特徵圖提取中的K,並去掉池化操作其中,n是一個膨脹因子,決定KD中0元素的數目

RNN雖然天生適合NLP,但是它也有些明顯的缺點,比如難以並行化,耗費計算資源如果在最後一步輸出,那麼模型經常會過度關注最後一步的輸入只在最後一步輸出的RNN而卷積神經網路(Convolutional Neural Network, CNN

在給定一箇中間特徵圖(intermediate feature map)的情況下,我們的模組沿著通道和空間兩個單獨的維度依次生成注意力對映,然後將注意圖乘到輸入特徵圖中進行自適應特徵細化

其實, 就是我們經常看到的圖4,利用卷積實現了局部連線,然後輸出資料裡的每個神經元透過同一個卷積核(共享權重)去卷積影象後再加上同一個偏置(共享偏置)得到的,如果沒有用共享權值,那麼一個神經元需要對應一個卷積核一個偏置,而現在是每個神經元對

最後,作者改進ASPP,當輸出步長等於16,ASPP包括一個1×1卷積和三個3×3卷積,其中3×3卷積的孔的比率(所有的濾波器個數為256且加入了batch normalization),和影象級特徵,如下圖所示
最近專攻存算分離和DB On K8s方向,因此讀一些相關的論文,做一些筆記摘要shared-nothing架構下的LSM-based 資料庫在吞吐量和延遲之間的瓶頸主要在:不同分片資料不均衡,某些熱點資料處理壓力大後臺進行flush/com

三、卷積神經網路結構在自然語言處理的應用首先我們來介紹第一篇論文《Natural Language Processing (almost) from Scratch》,該論文主要是針對原來那種man-made 的輸入特徵和人工特徵,利用神經

Lili Mou等2015年提出過一個TBCNN,就是用CNN去學程式碼的AST:先把AST編碼為向量,然後用基於樹的卷積層去學習特徵

需要準備的開發環境:python 3.x,TensorFlow,Keras
由於卷積操作透過將跨通道和空間資訊混合在一起來提取資訊特徵,因此我們採用我們的模組來沿著這兩個主要維度強調有意義的特徵:通道(channel)軸和空間(spatial)軸
構建一個 CNN 架構意味著我們需要設定許多超引數,其中有些是我們上面提到的:輸入表示(word2vec,GloVe,one-hot)、卷積濾波器的數量和尺寸、池化策略(最大池化、平均池化)以及啟用函式(ReLu、tanh)