上次看到有人說liggle查詢destroy的同義詞結果查到了protect,感覺不是特別準確,其實查同義詞可以用多種方法,可以交叉使用多個查同義詞網站,快速地獲取同義詞,輔助外語教學、英語寫作和詞義辨析

這就是對某個事物的滿意度,所以原句正確的寫法是:satisfaction with the museum2) disappointing/disappointed現在分詞VS過去分詞開啟語料庫網站,搜尋disappointing, 得到:L

07、本是青燈不歸客,卻因濁酒戀紅塵,星空不問趕路人,歲月不負有心人
但是人工整理也會帶來許多錯誤,不一致,所以高質量的語料庫一定是人機互助、不斷改進的
如題如果定冠詞the不能獨立充當句的成分,那麼以下例句是否是省略了後面的某個絕對不會被誤解的名詞
練習時首先泛聽一到三次,全域性領悟聽力材料內容,接下來進行精聽訓練,逐句到逐詞漸進深入,把從握內容到結構瞭解,直到完全聽懂
出於音律等考量在特殊文體中也有特例:我的將軍啊 你究竟去了哪啊 你說你去把敵殺啊 何故你不回家 ——歌曲《我的將軍啊》杜甫川唱來柳林鋪笑 紅旗飄飄把手招 ——賀敬之《回延安》BCC語料庫:火車票難求,飛機又太貴,曲線救國繞

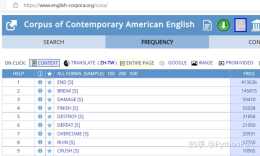
最簡單的語料庫就搜尋引擎,Google不好上,就用Bing好了,記得選上只看English網頁就好:當然你也可以使用專業的語料庫網站,看看你想使用的搭配的頻率,頻率為0或者頻率太低的不要用,比如:Corpus of Contemporary

詞與詞之前沒有空格進行區分,因此中文分詞需要語料庫的支撐 語料庫線上可以下載到官方語料庫詞頻表,統計2000萬字出現頻率大於50次的詞,一共14629 詞語

當時因為對整套的理論框架還不能完全掌握,閱讀的文獻十分有限,加上沒有接受過圖表製作及論文寫作的嚴格訓練,於是在文獻綜述部分基本是拼湊,圖表設計上也很粗糙,文章結構性問題都很突出,而且談了很多諸如文化負載等很寬泛甚至完全不搭邊的東西去湊字數,
開放的聊天語料庫很少,質量也需要根據需求評估一下,一些已知的庫可以在 Samurais/Dialog_Corpus 找到

在翻譯工作和學習的過程中,需要去查證很多的背景知識和術語內容
CCL沒有提供歷時檢索功能,BCC有,所有想做歷時分析、對比的,就只能選BCC啦
如何實現批次識別並儲存在文字中:python呼叫Tesseract批次識別圖片並輸出識別時間待續第三步:訓練一張圖片的語料庫:在寫這篇文章我看了幾十篇部落格,最詳細的基本上就是這篇文章了
如果真的不行就放棄吧作為聽力老師我認為大機率事件是在聽力過程中沒有掌握題目和聽力材料之間的關係

三、閱讀材料:《劍橋雅思真題》使用方法:第一步:做題在具備了一定單詞量的情況下,先根據解題思路認真做題,做完後核對答案

主題提取機器翻譯多模式語料庫的Alignment(例如,影片索引)六、N-gram模型* 這是資訊搜尋的基本模型,雖然是粗略計算,但易於計算機操作、負載小數理方法:隱馬爾可夫模型(如文章開頭連結的文章裡寫的模型就是)KWIC列表(Key W
四、小結在文章最後,除在第二部分給出的結論外,作者列出了一些從其他文獻中得到的簡單的結論:Word2vec嵌入在私人臨床筆記、PMC、維基百科和谷歌新聞語料庫上進行了定性和定量培訓,並顯示在大多數測試場景中,接受電子健康記錄資料培訓的嵌入表
特殊詞彙表與其列出一長串不相關的單詞來學習,不如列出具體特殊的單詞來學習,可以對工作、學習或愛好中所需詞彙進行針對性的準備
如果一個詞的出現與它周圍的詞是獨立的,則稱之為一元語言模型(unigram)如果一個詞的出現僅依賴於它前面出現的一個詞,則稱之為二元語言模型(bigram)如果一個詞的出現僅依賴於它前面出現的兩個詞,則稱之為三元語言模型(trigram)4