決策樹:機率,熵,Gini係數,KNN演算法:距離函式K-Means演算法:距離函式主成分分析:協方差矩陣,散佈矩陣,拉格朗日乘法,特徵值與特徵向量線性判別分析:散佈矩陣,逆矩陣,拉格朗日乘法,特徵值與特徵向量流形學習:流形,最最佳化,測地
如 @lixin liu 所說的指數分佈族等等可以保證似然函式是global strictly concave的問題,Critical Points(導數為0的點)一定是唯一極大值點(於是是最大值點),那自然是沒有問題的
具體做法如下:設總體的分佈函式形式已知,其中含有一個未知引數,首先從總體中抽取樣本,然後按照一定的方法構造合適的統計量作為的統計量,記為,代入樣本觀測值,即得到的估計值
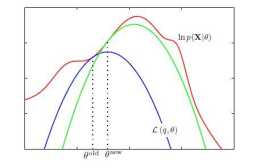
用數學 表述 則是 ,對於凸函式,總有:那麼考慮對數似然:根據Jensen不等式得到了對數似然的一個下界,所以我們只要最大化這個下界即可,而我們最大化的目標引數是,與無關,所以實際上只需要最大化下面的式子:很容易得到這就是上面的Q函式,所以
θ)的表達,對於這個機率表示式一直理解的不清楚,於是在網上查閱資料,整理如下:我們先來逐個分析裡面的每一個變數

結構風險最小化採用了最大後驗機率估計的思想來推測模型引數,不僅僅是依賴資料,還依靠模型引數的先驗假設

交叉熵、均方差損失函式,加正則項的損失函式,線性迴歸、嶺迴歸、LASSO迴歸等迴歸問題,邏輯迴歸,感知機等分類問題、經驗風險、結構風險,極大似然估計、拉普拉斯平滑估計、最大後驗機率估計、貝葉斯估計,貝葉斯公式,頻率學派、貝葉斯學派,機率、統

極大似然的有偏性極大似然估計方法求解引數有一定侷限性,極大似然法除了會得出第1節中關於硬幣的極端情況外,還會出現一種情況,有偏估計,就是期望理想值
根據邊緣機率和聯合機率密度的定義,是對所有可能的的積分,即又根據條件獨立性有因此可以得到預測的分佈由於根據模型本身有,根據貝葉斯定律,有(其中和前面已有推導),則代入計算(比較複雜沒有推),有期望值仍然是MAP估計的值,但是現在可以得到方差

的引數表示混個高斯分佈的期望和協方差矩陣,具體如下所示:其中表示任意一個節點屬於社群的機率,也相當於一種先驗

所以,最大似然估計從資訊理論的角度來看, 是在最小化產生觀測資料的分佈 #FormatImgID_46# 和模型分佈 #FormatImgID_47# 之間的交叉熵, 即均方誤差損失與最大似然估計在實際生產中, 我們經常使用MSE(Mean
相關性質:由於”最大似然估計法“得到的結果(估計量)為一個含有未知引數的代數方程,不一定有顯式解,因此研究它的無偏性、相合性比較困難
我知道AIC、BIC的統計解釋是“似然函式+模型複雜度懲罰”,AIC的模型複雜度懲罰是2倍引數個數,BIC的模型複雜度是乘以引數個數,所以BIC對模型複雜度的懲罰更厲害,更傾向於選擇帶有更少引數的模型

μ, σ) 它的意思是「在模型引數μ、σ條件下,觀察到資料 data 的機率」
接著,我們試著把基於最大似然的邏輯迴歸改造成基於最大後驗估計的邏輯迴歸,但提前需要定義好引數的先驗
這兩類問題解決思路都是先假設觀察值與預測值之間存在某種聯絡,然後使用模型來表示這種聯絡,進而透過最佳化目標函式值來確定模型引數,從而得到最終的模型
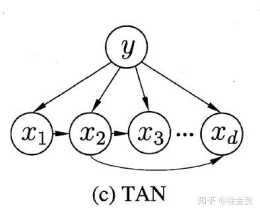
如果表示訓練集中第類樣本組成的集合,那麼可容易的估計出類先驗機率:類先驗機率能夠簡單求解,下面是類條件機率:針對離散屬性而言,令表示在中第個屬性取值為的樣本組成的集合,那麼類條件機率為:針對連續屬性而言,可考慮機率密度函式,假定,其中分別是
填空題中倒求一階常微分方程的解連著出了很多,應該好好掌握

有了上述與之間的關係,透過解微分方程,我們得到了的數學形式:推導過程本節主要是來推導的形式, 所謂的推導過程,就是求解微分方程的過程,整個計算過程如下圖所示:需要明確的一點,是關於的函式,那麼中的也可以認為是關於的函式,這樣才方便理解下面的

也就是說,EM 演算法透過引入隱含變數,使用 MLE(極大似然估計)進行迭代求解引數