size()))#print(probs)batch_loss=-alpha*(torch

0/batch_size))# mul_() ternsor 的乘法 正確的數目/總的數目 乘以100 變成百分比returnrtn迭代訓練函式訓練中使用tensorboard來繪製曲線,終端輸入tensorboard ——logdir=

因此,為了提取準確的語義邊界,作者採用語義邊界作為顯式監督,使網路學習具有較強的類間獨特效能力的特徵B-Net整體結構為bottom-up結構
使用者模式的連線函式遠端登入到其它裝置的命令一般在使用者模式執行,常用的遠端登入方式有3種:Telnet、SSH、叢集,所以寫3個連線函式:網路裝置指令碼/基礎介面/使用者模式

我給忘了頁面程式碼我會在最後釋出首先我們需要選擇你用的棋子然後設定誰是先手#FormatImgID_3##FormatImgID_4#然後開始遊戲,簡單吧我們需要完成:選擇棋子選擇角色點選棋盤(注意:只有人才需要點選 )注意:使用點選事件中
linear_q(x)# batch, n, dim_kk=self

g, features, labels, num_classes, train_idx, val_idx, test_idx, train_mask, \val_mask, test_mask = load_data(args[‘datas
connect(“localhost”,“root”,“123456”,“pythondb”)cur=conn
sess = tf

metrics import accuracy_score# 返回準確率precision = accuracy_score(y_true, y_pred, normalize=True)# 返回正確分類的數量precision_num =

特點:純NumPy實現,依賴簡單、部署快捷非常精簡的IR實現,基於JSON自帶模型視覺化(基於networkx)支援模型從PyTorch自動轉換比較豐富的示例CNN模型頂層設計:我們要設計一個神經網路推理框架,首先要先把框架的頂層設計想好
shape[0])SVM = SmoSVM(train=train, alpha_list=init_alphas, kernel_func=kernel, cost=0
__init__(in_channels, out_channels, kernel_size, stride, padding, dilation,False, _pair(0), groups, bias, padding_mode)d

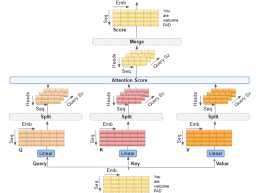
還有一些小訣竅真正現代的transformer模型裡用到的self-attention實際上還用到了三個小技巧:1)Queries, keys and values每個input vector都在self attention裡被用作三種不同

send# 回撥函式為 生成器的 send 方法,當然這種寫法有問題,此時生成器還未形成do_something(callback)# 進行 io 操作,並將 callback 註冊為回撥函式result=yieldreturnresult

speed=max(3-self

shape))(1, 64, 8, 8)(1, 128, 4, 4)(1, 256, 2, 2)(1, 512, 1, 1)”“”arch_settings={18:(BasicBlock,(2,2,2,2)),34:(BasicBlock
Module):def__init__(self,alpha=None,gamma=0,smooth_eps=0,class_num=2,size_average=True):super(LabelSmoothFocalLoss,self)
collect_params(), ’sgd‘,{’learning_rate‘: 0

pos_ffn(dec_outputs)# dec_outputs: [batch_size, tgt_len, d_model]returndec_outputs,dec_self_attn,dec_enc_attndecoder兩次呼叫