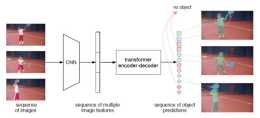
對於每一幀,將decoder輸出的instance preidiction和對應幀的encoder得到的feature輸入到一個self-attention模組中,得到初始的attention map
)forward 函式接收引數:source sequence 、source position 、target sequence、 target position方法過程:呼叫encoder(關聯Encoder類) ——> 呼叫de
Attention Model中也使用block(分塊)的方式來解決這一的問題[3],每個block輸出對應的yb,其中每個block結尾會輸出一個作為這個block的結束,具體方式如下:首先把長度為T的序列分成長度為W的block,這樣b

CIGAR中的數字代表鹼基的個數,字元的含義見下表:舉個栗子:3M1D2M1I1M:3個鹼基匹配(M)(3M)、接下來1個鹼基缺失(D)、接下來2個匹配(2M)、接下來1個鹼基插入(1I)、接下來1個鹼基匹配(1M),如下圖:第七列、RNE
Runtime程式碼架構首先,Sequence執行時相關部分程式碼位於UnrealEngine\Engine\Source\Runtime\MovieScene下:除了根目錄下的標頭檔案外,可以看到整體結構組織中大致分為了Channels、
mean(accs)return {“acc”: 100*acc, “f1”: 100*f1}# 給佔位符填值def get_feed_dict(words, labels_value=None):word_ids_value, seque

本實驗利用UniLM的sequence-to-sequence模型來完成,在 CNN/DailyMail 資料集上完成摘要任務,在訓練集上fine-tuning 30個epochs,微調的超引數與預訓練的時候一致,target token被

在彈出的“腳註選項”對話方塊中,要進行相關設定,請參考下圖自行嘗試:以上這種腳註相對比較容易做,要是想做出下圖這種帶圈的數字腳註,就要難一些了:首先,它需要在電腦中安裝一款特別的字型檔:Rope Sequence Number ST (或者

如果您覺得我說的還有點意思,請點贊讓我感到您的支援,您的支援是我寫作最大的動力~ijournal:高顏值的期刊檢索網站,助您快速找到理想目標期刊(weixin小程式也上線了哦)投必得:全專業中英文論文潤色編輯助力您的論文快速發表,點選瞭解業
在伯努利實驗裡,有 2 類主要問題:首次成功時的實驗 n 次的機率 —— 幾何分佈N 次實驗中的成功 S 次的機率 —— 二項分佈有趣的延伸,Bernoulli process 的 sequence 都是二進位制的,可以看作是一個數字的二進