
部分答案及參考文章:Passage 1:資訊傳播的發展題型搭配:判斷+填空原文待補充:答案參考:1

所以賓語的定義是:a noun, noun phrase or pronoun that refers to a person or thing that is affected by the action of the verb (cal

observation_space)9print(env
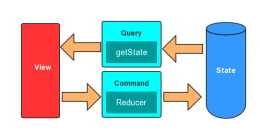
拿宇宙來說,如果我們有一個可以記錄宇宙所有狀態的相機,那麼按下一次快門所記錄的就是宇宙的一個 State,下一刻就是一個 Transition,宇宙的運轉就是一個無限狀態機,除非哪一刻宇宙毀滅了:一個 SPA 也可以用狀態機模型來描述:St
2006——Notes on Convolutional Neural Networks2011——Large displacement optical flow_ descriptor matching in variational mo
saved_log_probs, returns):policy_loss

Pac-Man首先要安裝一些環境$ brew install cmake boost boost-python sdl2 swig wget$ pip3 install ——upgrade ‘gym[all]’你可以建立一個吃豆人小姐的環境

由於很難求,所以將上式轉化成變分下界的形式,項透過SAC策略訓練時最大化動作的熵解決了,後面那項直接作為強化問題的pseudo-reward去最佳化policy,這樣agent會在訪問到更容易被區分的state時得到獎勵,同時更新discr

最終結果可以看到,在不使用麥克風的時候,說話的聲音與邊上地鐵透過時的聲音音量基本相當,不得不說大疆Osmo Action自身的收音還是不錯的,在這樣的環境下,至少可以保證清晰的收音,但如果作為vlog來說,效果可能會不那麼理想
2沒有熵正則化的關鍵方程為了讓 SAC 演算法與離散動作空間一起工作,需要調整兩個關鍵方程: 策略 π 的引數 θ 的(actor)成本函式 Q 函式 的引數 φ 的(critic)成本函式 它們分別來自最優策略和 Q 函式的定義
我比較喜歡的結構是:action,background, conflict, deep thinking, and endingAction:還記得你想寫的那段故事嗎
因為某些原因,苦主沒有起訴他老婆的情人Action當然也可以單純的指某種行為,此時它的意思相當於behavior乮15乯His action was suspicious,to come to think of it說起來,他的行為的確有些
In other words, emotional needs create motivation, which drives people to take actions

回想一開始的目標是要得到隨機梯度上升的形式,且希望樣本梯度的期望恰好為度量函式的梯度,而 policy gradient theorem 給出的公式恰好滿足,注意到公式右側是一個關於(其含義是在服從策略時,各狀態 s 發生的機率)的加權和,
強化學習相比於深度學習可以解決一些問題:很難去對資料進行label,因為是一個序列,如果把整個序列作為輸入,那需要的training是龐大的,指數級別的

如果我們在 A 工具欄中,建立了一個 Action,執行 Toolbars: Switch to toolbar B 的命令(我們可以把這樣的操作簡稱為A→B)

是否隱藏和禁用apk/*** only hide app but don‘t delete user data** @param pkgName*/private void hide(String pkgName) {final Packa
三、當場記板落下的那一秒(準確說應該是幀),有“啪”的一聲,場記板的材質會使這個聲音特別響亮、乾脆,在後期剪輯的時候就根據這個聲音確定時間點

jsp繼承ActionSupport在其中封裝了execute方法,我們只需要覆蓋即可在這個類中還預設的封裝了一些靜態變數,比如:public static final String EOORO=”error”public static f

struts2使用標準的context來進行OGNL表示式的語言求值,OGNL的頂級物件是stackContext(map型別-資料結構),其根物件就是valueStack(當系統建立action例項後,該Action例項已經儲存到valu