
上表是對每一行資料做了卡方擬合優度檢驗後整理的結果,過程如下:以上圖為例:上圖中的卡方值和P值,就是對每一行資料都進行了卡方擬合優度檢驗,然後整理成一張表格,這裡分享使用SPSSAU-資料科學分析平臺來分析資料得出結果,然後製作一下這張表

無關性假設舉個例子,假設我們有一堆新聞標題,需要判斷標題中包含某個詞(比如吳亦凡)是否與該條新聞的類別歸屬(比如娛樂)是否有關,我們只需要簡單統計就可以獲得這樣的一個四格表:組別屬於娛樂不屬於娛樂合計不包含吳亦凡192443包含吳亦凡341

這個時候每一個格子的期望值可以這麼計算:期望值=期望機率*頻數假設刷酸出現的次數跟月份沒有關係,則刷酸出現的機率應該為100/200=1/2,則8月份出現刷酸的文字期望數應該為8月分的總文字數刷酸出現的機率=1/2*100=50,則第一行第

六、劃重點1、當研究資料分成兩組,結局變數為二分型別資料,可採用卡方檢驗或Fisher確切機率法
與發現高斯分佈(正態分佈)一樣,開始的開始只是一個巧合,即統計學家發現從正態分佈中抽取樣本(比如身高),然後取身高得平方,再之後神奇的事發生了,這個由樣本值取平方形成的分佈與以往的正態分佈不同,而且透過一頓實驗與統計計算,發現這個分佈的引數
基本原理卡方檢驗就是統計樣本的實際觀測值與理論推斷值之間的偏離程度,實際觀測值與理論推斷值之間的偏離程度就決定卡方值的大小,如果卡方值越大,二者偏差程度越大

①分層卡方檢驗彙總表格上表格展示各個分層(以及不分層)情況下時,各交叉類別項的資料情況,以及輸出OR值和fisher卡方值,比如不分層時,即完全不考慮性別時,‘是否吸菸’與‘是否感冒’之間呈現出顯著性(χ2=15

05,因此可以拒絕原假設(各學科人數滿足2:2:1的分佈比例),可以認為樣本來自的總體與指定的理論分佈存在顯著差異,及所調研資料的學生所學學科的理科、文科、藝術類的分佈比例不滿足2:2:1在 SPSS學堂 中回覆20180227,可獲得本次
所以我們推論的卡方統計量為:真正的卡方統計量為:欲證,只需只需(是單位矩陣)又因為所以顯然(^^)所以證得總結一下,卡方獨立性檢驗的公式由來就是:在A、B變數獨立的原假設下,將列聯表中的變數(正態分佈)用線性變換去除相關性(等同於獨立,見定

test_nominal_association()方法用於檢驗交叉表中變數的獨立性,原假設是認為變數之間是獨立的
05且有極端異值對總體引數進行描述對總體引數進行描述對總體分佈進行描述描述:均值、標準差描述:均值、標準差描述:中位數、四分位數、間距描述引數檢驗:T檢驗,F檢驗(方差分析)引數檢驗:T檢驗,F檢驗(方差分析)非引數檢驗:秩和檢驗10/6成
SPSS內部提供了多種分析資料相關性的方法:卡方檢驗(Chi-SquareTest),Pearson相關係數計算,Spearman相關係數計算和Kendall的tau-b(K)相關係數計算
我們以泰坦尼克號資料集(Titanic)為例,它包含:存活或死亡的乘客數Survived-No/Yes乘客的船艙等級Class(一等1st、二等2nd、三等3rd和船員Crew)性別(男性Male、女性Female)年齡層(兒童Child、
卡方分佈臨界值表:根據自由度,找到>的值,找到對應的機率P,表示原假設成立的機率所以卡方檢驗的值越大越好,越大表示拒絕原假設的機率越大

chi2_contingency(observed=observed)可以看出P值要小於我們原先定的顯著性水平α,所以我們有理由拒絕原假設,即使用者渠道的確影響了留存情況,兩者並不是相互獨立的
回憶其定義若是多元正態分佈的隨機向量,則上述標準化後求平方和就直接是服從等於變數個數的自由度的卡方分佈統計量
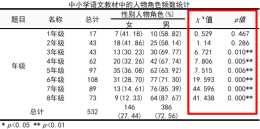
情況二、做了卡方擬合優度檢驗後整理以上圖為例:上圖中的卡方值和P值,就是對每一行資料都進行了卡方擬合優度檢驗,然後整理成一張表格,這裡分享使用SPSSAU來分析資料得出結果,然後製作一下這張表

二、對問題的分析研究者想分析多種購房人型別與多種房屋型別的關係,建議使用卡方檢驗(R×C),但需要先滿足3項假設:假設1:存在兩個無序多分類變數,如本研究中購房人型別和房屋型別均為無序分類變數

根據《醫學統計學》(孫振球主編)教科書上的介紹,分層分析OR值可採用Mantel-Haenszel方法進行估計,並用Mantel-Haenszel卡方檢驗的χ2統計量直接對OR值進行假設檢驗,同時採用Miettinen法計算OR值的95%可

Mantel-Haenszel卡方檢驗結果顯示疼痛症狀數量與疼痛等級間存線上性關係,χ2=56