機器學習(周志華)課後習題——第四章——決策樹
4.1 試證明對於不含衝突資料(即特徵向量完全相同但標記不同)的訓練集,必存在與訓練集一致(即訓練誤差為 0) 的決策樹。
答:
從原書p74的圖4。2的決策樹學習的基本演算法可以看出,生成一個葉節點有三種情況:
1、節點下樣本

全屬於同一類樣本

,則將當前節點作為
類葉節點。
2、屬性集

,或者樣本在當前屬性集上取值相同。即特徵用完了(當只剩最後一個特徵時,進一步分裂,只能將各取值設立葉節點,標記為樣本最多的類別。),或者的樣本在

上取值都相同(感覺這裡貌似和第 一條重複了)。這時取
中最多的類作為此節點的類別標記。
3、在某一節點上的屬性值

,樣本為空,即沒有樣本在屬性

上取值為
。同樣取
中最多的類作為此節點的類別標記。
在這道題中,目標是找出和訓練集一致的決策樹,所以不必考慮第3點,從1、2情況來看出決策樹中樹枝停止“生長”生成葉節點只會在樣本屬於同一類或者所有特徵值都用完的時候,那麼可能導致葉節點標記與實際訓練集不同時只會發生在特徵值都用完的情況(同一節點中的樣本,其路徑上的特徵值都是完全相同的),而由於訓練集中沒有衝突資料,那每個節點上訓練誤差都為0。
4.2 試析使用"最小訓練誤差"作為決策樹劃分選擇準則的缺陷。
答:
這道題暫時沒想出答案。在網上找了其他的答案,都是認為會造成過擬合,沒給出具體證明。而我的理解決策樹本身就是容易過擬合的,就算使用資訊增益或者基尼指數等,依舊容易過擬合,至於使用“最小訓練誤差”會不會“更容易”過擬合暫時沒理解明白。
待填坑。
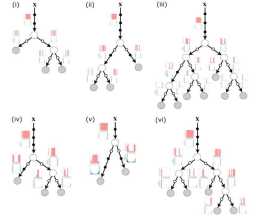
4.3 試程式設計實現基於資訊熵進行劃分選擇的決策樹演算法,併為表 4.3 中資料生成一棵決策樹。
答:
因為資料集的原因,資料量比較小,在選擇劃分屬性的時候會出現特徵的資訊增益或者資訊增益率相同的情況。所有生成的決策樹和書中可能不一致。並且在生成葉節點時,會出現兩類數量一直的情況,這時候葉節點就隨機設定一個分類了。
程式碼實現了以資訊增益、增益率、基尼指數劃分準則。下面一道題(4。4)也是用相同的程式碼。另外畫圖的程式碼是主要參考《機器學習實戰》決策樹那一章畫圖原始碼。
有些地方程式碼有點亂,比如進行剪枝的部分就有大量重複程式碼;並且預剪枝部分可以在生成決策樹的時候實現,減少計算量。以後有機會再最佳化一下。
程式碼在:han1057578619/MachineLearning_Zhouzhihua_ProblemSets
生成決策樹如下:

4.4 試程式設計實現基於基尼指數進行劃分選擇的決策樹演算法,為表 4.2 中資料生成預剪枝、後剪枝決策樹並與未剪枝決策樹進行比較.
答:
han1057578619/MachineLearning_Zhouzhihua_ProblemSets
未剪枝、後剪枝、預剪枝生成決策樹分別如下,總體來說後剪枝會相比於預剪枝保留更多的分支。
有兩個需要注意的地方。一個是在4。3中說過的,因為劃分屬性的資訊增益或者基尼指數相同的原因,這個時候選擇哪一個屬性作為劃分屬性都是對的,生成決策樹和書中不一致是正常的(書中第一個節點為“臍部”)。另外資料量這麼小的情況下,常常會出現剪枝前後準確率不變的情況,原書中也提到這種情況通常要進行剪枝的,但是這道題中若進行剪枝,會出現只有一個葉節點的情況。為了畫圖好看點。。。所以都不無論在預剪枝還是後剪枝中,這種情況都會採取不剪枝策略。參考原書P82。
經過測試,在未剪枝的情況下,驗證集上準確率為0。2857;後剪枝準確率為0。5714;預剪枝也為0。5714。

未剪枝

後剪枝

預剪枝
4. 5 試程式設計實現基於對率迴歸進行劃分選擇的決策樹演算法,併為表 4.3 中資料生成一棵決策樹.
答:
這個沒實現。
一種思路就是擬合對率迴歸後,從所有特徵中選擇一個

值最高的一個特徵值,即權重最高的一個特徵值作為劃分選擇,但是沒想好對於One-hot之後的特徵權重怎麼計算,比如“色澤”有三種取值“烏黑”、“青綠”、“淺白”,在One-hot之後會有三個特徵,那麼最後“色澤”這個特徵的權重應該是取平均值?以後有機會。。。。也不填坑。
4.6 試選擇 4 個 UCI 資料集,對上述 3 種演算法所產生的未剪枝、預剪枝、後剪枝決策樹進行實驗比較,並進行適當的統計顯著性檢驗.
答:
只拿sklearn中自帶的iris資料集試了一下剪枝後的準確率,發現不同隨機數種子(使得資料集劃分不同)導致最後驗證集的準確率變化挺大。
統計顯著性檢驗沒實現。
han1057578619/MachineLearning_Zhouzhihua_ProblemSets
4.7 圖 4.2 是一個遞迴演算法,若面臨巨量資料,則決策樹的層數會很深,使用遞迴方法易導致"棧"溢位。試使用"佇列"資料結構,以引數MaxDepth 控制樹的最大深度,寫出與圖 4.2 等價、但不使用遞迴的決策樹生成演算法.
答:
主要思路每一次迴圈遍歷一層下節點(除去葉節點),為每一個節點生成子節點,將非葉節點入隊;用引數L儲存每一層有多少個節點。下一次迴圈執行同樣的步驟。直至所有的節點都葉節點,此時佇列為空。具體如下:
輸入:訓練集D = {(x1, y1), (x2, y2)。。。(xm, ym)};
屬性集A = {a1, a2。。。 ad};
最大深度MaxDepth = maxDepth
過程:函式TreeDenerate(D, A, maxDepth)
1: 生成三個佇列,NodeQueue、DataQueue、AQueue分別儲存節點、資料、和剩餘屬性集;
2: 生成節點Node_root;
3: if A為空 OR D上樣本都為同一類別:
4: 將Node_root標記為葉節點,其標記類別為D中樣本最多的類;
5: return Node_root;
6: end if
7: 將Node入隊NodeQueue; 將D入隊 DataQueue; 將A入隊AQueue;
8: 初始化深度depth=0;
9: 初始化L = 1; # L用於記錄每一層有多少非葉節點。
10: while NodeQueue 非空:
11: L* = 0
12: for _ in range(L): # 遍歷當前L個非葉節點
13: NodeQueue 出隊Node; DataQueue出隊D; AQueue 出隊A;
14: 從A中選擇一個最優劃分屬性a*;
15: for a* 的每一個值 a*v do:
16: 新建一個node*,並將node*連線為Node的一個分支;
17: 令 Dv表示為D中在a*上取值為a*v的樣本子集;
18: if Dv為空:
19: 將node*標記為葉節點,其標記類別為D中樣本最多的類;
20: continue;
21: end if
22: if A\{a*}為空 OR Dv上樣本都為同一類別 OR depth == maxDepth:
23: 將node*標記為葉節點,其標記類別為Dv中樣本最多的類;
24: continue;
25: end if
26: 將node*入隊NodeQueue; 將Dv入隊 DataQueue; 將A\{a*} 入隊AQueue;
27: L* += 1; # 用於計算在第depth+1 層有多少個非葉節點
28: L = L*;
29: depth += 1;
30: return Node_root;
輸入以Node_root為根節點的一顆決策樹
4.8 試將決策樹生成的深度優先搜尋過程修改為廣度優先搜尋,以引數MaxNode控制樹的最大結點數,將題 4.7 中基於佇列的決策樹演算法進行改寫。對比題 4.7 中的演算法,試析哪種方式更易於控制決策樹所需儲存不超出記憶體。
答:
4。7寫的演算法就是廣度優先搜尋的。這道題將MaxNode改為MaxDepth,只需要改幾個地方。有一點需要注意的地方,就是在給一個節點生成子節點時(19-32行),可能造成節點數大於最大值的情況,比如某屬性下有3種取值,那麼至少要生成3個葉節點,這個時候節點總數可能會超過最大值,這時最終節點數可能會是MaxNode+2。
至於兩種演算法對比。個人理解當資料特徵值,各屬性的取值較多時,形成的決策樹會趨於較寬型別的樹,這時使用廣度優先搜尋更容易控制記憶體。若屬性取值較少時,深度優先搜尋更容易控制記憶體。
對4。7中修改如下:
輸入:訓練集D = {(x1, y1), (x2, y2)。。。(xm, ym)};
屬性集A = {a1, a2。。。 ad};
最大深度MaxNode = maxNode
過程:函式TreeDenerate(D, A, maxNode)
1: 生成三個佇列,NodeQueue、DataQueue、AQueue分別儲存節點、資料、和剩餘屬性集;
2: 生成節點Node_root;
3: if A為空 OR D上樣本都為同一類別:
4: 將Node_root標記為葉節點,其標記類別為D中樣本最多的類;
5: return Node_root;
6: end if
7: 將Node入隊NodeQueue; 將D入隊 DataQueue; 將A入隊AQueue;
8: 初始化深度numNode=1;
9: 初始化L = 1; # L用於記錄每一層有多少非葉節點。
10: while NodeQueue 非空:
11: L* = 0
12: for _ in range(L): # 遍歷當前L個非葉節點
13: NodeQueue 出隊Node; DataQueue出隊D; AQueue 出隊A;
14: if numNode >= maxNode:
15: 將Node標記為葉節點,其標記類別為D中樣本最多的類;
16: continue;
17: end if;
18: 從A中選擇一個最優劃分屬性a*;
19: for a* 的每一個值 a*v do:
20: numNode+=1
21: 生成一個node*,並將node*連線為Node的一個分支;
22: 令 Dv表示為D中在a*上取值為a*v的樣本子集;
23: if Dv為空:
24: 將node*標記為葉節點,其標記類別為D中樣本最多的類;
25: continue;
26: end if
27: if A\{a*}為空 OR Dv上樣本都為同一類別:
28: 將node*標記為葉節點,其標記類別為Dv中樣本最多的類;
29: continue;
30: end if
31: 將node*入隊NodeQueue; 將Dv入隊 DataQueue; 將A\{a*} 入隊AQueue;
32: L* += 1; # 用於計算在第depth+1 層有多少個非葉節點
33: end if;
34: L = L*;
35: return Node_root;
4.9 試將 4.4.2 節對缺失值的處理機制推廣到基尼指數的計算中去.
答:
這道題相對簡單。使用書中式4。9、4。10、4。11有,對於原書中4。5式可以推廣為:

,屬性a的基尼指數可推廣為:

。
4.10 從網上下載或自己程式設計實現任意一種多變數決策樹演算法,並觀察其在西瓜資料集 3.0 上產生的結果
答:
待補充。
上一篇:【26】——【30】
下一篇:男人如何長壽?