
以計算過程為例,即表示青年(5/15),剩下的中年和老年(10/15)為另一類

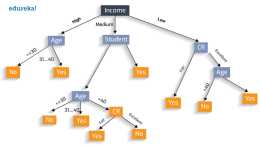
我們繼續使用上篇文章列舉的美國大選選民的資料來舉例:下圖是按照使用者的膚色進行分裂得到的多叉樹:ID3演算法的核心思想就是一個貪心演算法,每次選擇能夠帶來資訊增益最大的特徵進行分裂,但該資訊增益的值必須要達到事先設定的系統閥值,如果沒有達到

計算結果我們訓練了一個提升決策樹(boosted decision tree)模型以預測一個使用了 256 個決策樹、每個樹包含 32 個葉結點的通知點選機率
scikit-learn中的決策樹實現提供了一種使用以下選項停止構建樹的方法:min_samples_split: 指定在決策樹中建立一個新節點需要多少個樣本 min_samples_leaf: 指定了一個節點必須產生多少個樣本才會保留下來

主要方法實驗結果更多幹貨歡迎加入【3D視覺工坊】交流群,方向涉及3D視覺、計算機視覺、深度學習、vSLAM、鐳射SLAM、立體視覺、自動駕駛、點雲處理、三維重建、多檢視幾何、結構光、多感測器融合、VR/AR、學術交流、求職交流等
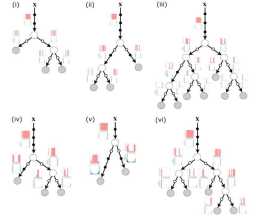
透過自適應神經樹(Adaptive Neural Trees,ANT),一種將表示學習嵌入到決策樹的邊、路徑函式以及葉節點的模型,以及基於反向傳播的訓練演算法(可自適應地從類似卷積層這樣的原始模組對結構進行擴充套件)將兩者進行結合
標的單位主要從事新藥研發的前期靶點發現和研究工作,而新藥開發的難度較高、風險較大,未來經營的不確定性較高,對公司整體進行收益法評估較難反映公司在研專案和技術儲備對公司估值的貢獻水平及未來的預期風險
R語言建立隨機森林現在,我們使用隨機森林來建立模型,解決決策樹預測結果不理想的問題

其中決策樹分類演算法是資料探勘中最為廣泛研究和應用的一個課題,由於在決策樹生成過程中,會過度擬合訓練資料,而且易受噪聲資料的影響,所以剪枝操作是決策樹生成過程中的一個重要步驟,MEP 剪枝法是其中的一種

看懂公式推導需要細心和耐心,同學們不要放棄~~AdaBoost 演算法原理及推導補充資料:AdaBoost原理詳解 - ScorpioLu - 部落格園4、優缺點Adaboost 演算法 的主要優點有:(1)泛化錯誤率低,精度高(2)基本無

比如,給出一張動物圖片,將它分類成貓或者狗)為了從資料中提取資訊,我們需要利用一些機器學習的模型(分類器),這些模型基本上可以看作是用來從給定的資料中尋找特定的模式,以便利用資料進行預測的演算法(看暈了

相比其他機器學習演算法,決策樹演算法對特徵選擇的可解釋性強,由於決策樹的分枝是採用閾值劃分的貪心策略,決策樹能很好的處理類別等離散特徵,且對於連續特徵的分佈沒有特殊的假設,大部分情況下不需要像其他機器學習或者深度學習演算法(SVM、線性迴歸
![決策樹剪的剪枝:REP [降低誤差剪枝法]](https://img.heatask.com/upload/thumbnail/2+ujze_xcGzAiFy1zNOk3OQAyY3o2tcSz0VRYuSNhsbJdYHI2q0s2clhzoR6yufTcFnhY3e=1Ah21Ysfd1gB3doU2T1kd+3U5zjnODSIhsGf2FWIgGXq2.jpeg)
本著這樣的目的,我們就構造一個新的,訓練決策樹時,沒有見過的資料集來測試決策樹,如果我們剪裁掉一些子樹,結果在新的沒見過的資料集上,錯誤率降低明顯,而在原資料集上錯誤率升高幅度不大,那麼我們說明我們剪下掉這些子樹是正確的
接下來對資料反覆進行遞迴劃分,直到劃分後的每個區域(決策樹的每個葉結點)只包含單一目標值(單一類別或單一回歸值)

99],flip_y=0,random_state=3)# define modelmodel=DecisionTreeClassifier()# define gridbalance=[{0:100,1:1},{0:10,1:1},{0:
我們一般認為決策樹模型:易於使用和解釋[6],單棵的決策樹很容易進行視覺化和規則提取可以自動實現特徵選擇[3] - 透過計算節點分裂時“不純度的降低”(impurity reduction) 和剪枝(pruning)預測能力有限,無法和強監
總結決策樹作為一類基礎而且常用的非線性分類和迴歸方法,我們在這裡介紹了決策樹常用的構建方法,包括其中幾種代表性的特徵選擇度量:資訊增益、資訊增益比、基尼指數和平方誤差,以及根據損失函式進行剪枝的方法,並結合起來介紹了由此衍生的代表性決策樹算
照此逐層劃分,直至結點中樣本個數小於預定閾值,或樣本集的Gini 指數小於預定閾值,或者沒有更多特徵,即停止生長,形成了一棵可進行分類預測的決策樹

如果我們選取特徵的順序分別是“資料”“模擬交易”“API”“回測”,那麼構建的決策樹就完全不同了

我們繼續使用上篇文章列舉的美國大選選民的資料來舉例:下圖是按照使用者的膚色進行分裂得到的多叉樹:ID3演算法的核心思想就是一個貪心演算法,每次選擇能夠帶來資訊增益最大的特徵進行分裂,但該資訊增益的值必須要達到事先設定的系統閥值,如果沒有達到