
unsqueeze(1)returnp此文除了計算以外,還額外計算了自身與自身的相似度,並稱為sentinel,如下式:程式碼表示為:# es=(Q*K)

所以下圖的同構情況不可能:所以我們事實上是隻能用下面的距離來表示一棵樹的:結果:樹的視覺化詞義資訊表達這一部分主要的猜想是BERT是否能區分不同上下文情況下的語境實驗1:使用詞的embedding簡單構建Nearest Neighbour訓

透過直接擴充套件FM,AFM引入Attention機制來學習不同組合特徵的權重,即保證了模型的可解釋性又提高了模型效能(但個人覺得這裡的缺點是使用了物理意義並不明顯的哈達瑪積)
2018年,Jian Liu,Yubo Chen,Kang Liu,Jun Zhao針對Event Detection任務中資料稀疏和單語歧義的問題,提出一種Gated MultiLingual Attention (GMLATT) 框架,

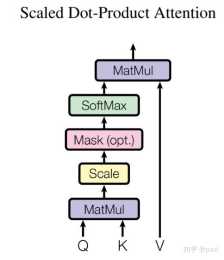
背景多頭自注意力層定義為輸入矩陣,包含個維的token,在NLP中,token對應著序列化的詞,同樣地也可以對應序列化的畫素自注意力層從到的計算如公式1, 2所示,為attention scores,softmax將score轉換為注意力概
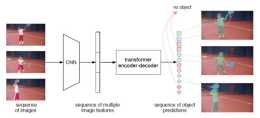
對於每一幀,將decoder輸出的instance preidiction和對應幀的encoder得到的feature輸入到一個self-attention模組中,得到初始的attention map
keras的實現很簡潔,fc+bn+glu同時實現,注意glu不是gelu,glu=x*sigmoid(x),實現的功能類似於LSTM中的門控機制自動進行特徵選擇(從這個層面上來看和注意力機制有異曲同工之妙),而gelu是參考 馬東什麼:關

因而,整個子結構就變成了:語言模型試驗過程中,對於使用transformer進行語言模型的建模中,還採用了幾種技術:相對位置編碼快取(Transformer-xl)自適應注意力寬度自適應softmax實驗結果在字元語言模型的效果如下:在wo
Universal Transformer 不像 RNN 那樣,每次輸入一個字元的embedding來進行時間迴圈,而是並行地使用多個self-attention 迴圈重複地修改句子中每一個符號的embedding表示
文章主要內容論文首先將基於注意力的模型在計算機視覺領域中的發展歷程大致歸為了四個階段:將深度神經網路與注意力機制相結合,代表性方法為RAM明確預測判別性輸入特徵,代表性方法為STN隱性且自適應地預測潛在的關鍵特徵,代表方法為SENet自注意
對於query和doc則各自得到intra-pooling,一共有5個attention,每個attention可以得到原始向量與attention互動後的向量,透過concat、哈達碼積和minus後,經過壓縮函式進入下一層(4) 前面5
to(device)],# -1)greedy_dec_predict=dec_input[:,1:]returngreedy_dec_predict按照上面的說法,如果我在程式碼中關掉了dropout,那麼當預測序列是時的輸出結果

1 綜述本篇文章,依然是對騰訊2020年的論文Learning to Build User-tag Profile in Recommendation System進行講解,如何使用深度學習模型代替傳統的統計方法,來準確地預測使用者對於標籤
Fully Connect然後全連線層算出user embeddingPredict Layer這點也是作者的一個創新點,如果按一般是直接news的embedding和user embedding內積作為預測結果,計算loss,但是因為1個

#FormatImgID_11##FormatImgID_12#△結構模組(Structure module)在這裡,研究人員同樣使用了Attention機制,它可以單獨計算蛋白質的各個部分,稱為“不變點注意力(invariant poin

還有一些小訣竅真正現代的transformer模型裡用到的self-attention實際上還用到了三個小技巧:1)Queries, keys and values每個input vector都在self attention裡被用作三種不同
Deep Speech 2在2016年公開,和DS1相比,聲學模型中加入瞭如下新的特性:引入卷積層用於特徵抽取,替代之前的全連線層,在時域和頻域的二維卷積可以明顯增強聲學模型在噪聲環境下的識別魯棒性RNN部分採用sequence-wise的
1 BottomUp Attention Model空間影象特徵V是很廣泛的,但是本文中我們基於檢測框來定義空間區域,進而實現bottom-op attention,Faster RCNN是一種目標檢測模型,用來確定目標例項是屬於某種類別然

而主要的區分點在於使用的decoder不同,這裡我就著重講一下tf.contrib.seq2seq.BeamSearchDecoder