
貢獻:+ 注意力機制網路改進網路,提升精度,略微降低速度:SENet (Squeeze-and-Excitation Network)圖2 改進,SENet嵌入到CSP中形成SE-CSP+ 負樣本訓練,提升精度,速度不變: NST (Neg

S2-BNN:基於蒸餾的自監督學習演算法京東AI開源CoTNet:用於視覺識別的上下文Transformer網路李沐等人提出UN-EPT:用於語義分割的統一高效金字塔TransformerICCV 2021 Oral | 何愷明團隊提出Mo

然後加入輔助loss,在原始的loss基礎上加入copy分佈和score分佈的KL散度(兩個分佈的擬合程度):4.RESULT模型在CNN/DM和Gigaword資料集上測試結果分別如下所示:CNN/DM資料集上的測試結果,其中Indegr

表 1:在 WikiText-103 上與 SoTA 結果的比較表 2:在 enwiki8 上與 SoTA 結果的比較表 3:在 text8 上與 SoTA 結果的比較表 4:在 One Billion Word 上與 SoTA 結果的比較

與之對應的,soft-attention就是對T進行加權,仍然是與LR越像權重越大,而這個權重也是簡單地來源於r,其實就是Q和K對應位置那個相似度:如下式,S是最終應用到了F、T concat再卷積的結果上,其中F是LR圖經DNN提取的Fe

TFT 是一種用於時間序列的多層純深度學習模型,該模型具有LSTM 編碼器-解碼器以及提供有可解釋預測的全新注意力機制

斯坦福大學——人工智慧本科4年課程清單超過500個附程式碼的AI/機器學習/深度學習/計算機視覺/NLP專案Awesome Transformer for Vision Resources List庫2020 Top10計算機視覺論文總結:

KD能夠以soft的方式將歸納偏置傳遞給學生模型,Deit中使用Conv-Based架構作為教師網路,將區域性性的假設透過蒸餾方式引入Transformer中,取得了不錯的效果
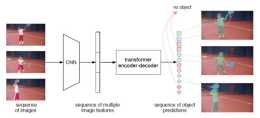
對於每一幀,將decoder輸出的instance preidiction和對應幀的encoder得到的feature輸入到一個self-attention模組中,得到初始的attention map

復旦提出SD-MAE:用於組織病理學影象分類的自蒸餾增強掩碼自編碼器CVPR 2022 | FAIR提出DVT:可變形影片Transformer何愷明團隊新作ViTDet:探索用於目標檢測的視覺Transformer骨幹網CVPR 2022

基於這個問題,今天給大家分享EMNLP2021頂會上的一篇文章,本篇論文的主要工作是建立在 SRU(一種高度並行化的 RNN 實現)之上, 作者結合了快速迴圈和序列建模的注意力機制, SRU++表現出強大的建模能力和訓練效率

因而,整個子結構就變成了:語言模型試驗過程中,對於使用transformer進行語言模型的建模中,還採用了幾種技術:相對位置編碼快取(Transformer-xl)自適應注意力寬度自適應softmax實驗結果在字元語言模型的效果如下:在wo
Universal Transformer 不像 RNN 那樣,每次輸入一個字元的embedding來進行時間迴圈,而是並行地使用多個self-attention 迴圈重複地修改句子中每一個符號的embedding表示
本文介紹了深度學習模型在時間序列預測問題中的應用,主要包括RNN、CNN、Transformer、Nbeats等4種類型模型,以及12篇相關頂會論文,全面掌握深度學習時間序列預測方法

以下是要寫的文章,本文是這個系列的第十九篇:Transformer:Attention集大成者GPT-1 & 2: 預訓練+微調帶來的奇蹟Bert: 雙向預訓練+微調Bert與模型壓縮Bert與模型蒸餾:PKD和DistillBer
簡單介紹一下我們組分子圖對比學習的工作哈論文題目:Molecular Contrastive Learning with Chemical Element Knowledge Graph論文連結:https://arxiv

構建完整個圖後,該模型可透過以下演算法更新引數:其中 GSA (Graph Self-Attention) 為:加入相對位置後,注意力的計算可修正為以下公式:A(u) 為所有與 u 節點相連的節點,由上面公式可見 GSA 其實就是多頭注意力
2、計算量大:計算複雜度與token的平方相關,如果輸入特徵圖為56*56的特徵圖,那麼會涉及3000+長寬的矩陣運算,計算量很大,同時在原始Transformer計算過程中token數以及hidden size保持不變,所以後來的研究者採

著名機器學習資源網站 Papers with Code 在 1 月 20 日釋出的 Newsletter 中列舉了近期應用 Transformer 的十大新任務:影象合成論文:Taming Transformers for High-Res

他們將DPT與該任務上的SOTA模型進行對比,採用的資料集包含約140萬張影象,是迄今為止最大的單目深度估計訓練集