
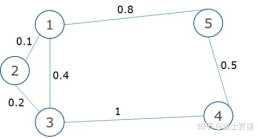
三、損失函式與拉普拉斯矩陣之前,我們定義了損失函式——被截斷邊的權重之和假設 G( V, E) 被劃分為 G1,G2 兩個子圖,設G有 n 個頂點定義 q = [] 是一個 n 維向量,用來表示劃分方案例如,按照上圖劃分,q = []分子可

經常引入專家對結果可理解性與價值進行評估資料探勘解決的問題資料預測、發現數據內在結構、發現關聯性、模式甄別資料預測:例如預測某個使用者是否留存或留存機率資料分類:獲得分類結果迴歸分析:得到數值解發現資料內在結構:例如使用者分群聚類發現關聯性
其基本思想是利用反映資料相似性關係的相似性矩陣計算拉普拉斯矩陣,然後選擇拉普拉斯矩陣的前k個特徵向量構成新的譜空間進行資料對映,透過特徵空間的對映轉化為傳統聚類演算法進行求解

為更好地挖掘使用者的出行規律,我們使用了機器學習中的Graph Embedding演算法構建CA graph,對CA的隱含特徵進行充分提取和描述,接著提出了一種BiLSTM-CNN模型實現對使用者區域位置的精準預測

DBSCAN演算法先任選資料集中的一個核心物件為“種子”,再由此出發確定相應的聚類簇,演算法虛擬碼如下:DBSCAN演算法演算法1-7行先根據給定的領域引數找出所有的核心物件

這個表,反應的是0-9一共10組尾數,同時出某一個個數號碼的組數分佈圖

無監督的聚類:Yading[1]是一種大規模的時序聚類方法,有別於K-Means和K-Shape採用互相關統計方法,它採用PAA降維和基於密度聚類的方法實現快速聚類,且在計算距離時儘量保留了時間序列的形狀

rand(k,1)returncentroids# k均值聚類演算法defkMeans(dataSet,k,distMeans=distEclud,createCent=randCent):m=shape(dataSet)[0]# 第一列儲

001, max_iter=100, init_params=‘kmeans’)n_components :高斯模型的個數,即聚類個數covariance_type : 透過EM演算法估算引數時使用的協方差型別:‘full’,‘tied’,

聚類中心選取方法:從輸入的資料點集合中隨機選擇一個點作為第一個聚類中心對於資料集中的每一個點x,計算它與最近聚類中心(指已選擇的聚類中心)的距離D(x)選擇一個新的資料點作為新的聚類中心,選擇的原則是:D(x)較大的點,被選取作為聚類中心的

當前,文字內容分析是網路資訊處理的關鍵技術,事實上,計算機能夠讀懂和分析文字資訊,核心就是透過對半結構化和非結構化文字資訊的挖掘與分析,從而實現對大規模網際網路文章或使用者文字資料進行分析,提取出文字特徵,並採用各種文字挖掘方法對特徵進行分

2,假定因變數y 與 k 個自變數之間為線性關係,並建立線性關係模型模型如下:3,對模型進行估計和檢驗估計引數的方法,可以用最小二乘法,計算得出的估計值4,判別模型中是否存在多重共線性,如果存在,進行處理參考描述題5,利用迴歸方程進行預測6
期刊簡介復現工具仙桃學術工具(https://www.xiantao.love/products)圖形復現進入仙桃學術,點選【生信工具】【高階版】 → 【立即使用】【表達差異(挑)】 → 【複雜數值熱圖】 →上傳資料我們參考文獻中的複雜數值

3) 對於任意的向量,我們有:4) 拉普拉斯矩陣是半正定矩陣,且對應的n個實數特徵值都大於等於0,即:Laplacians是譜聚類的核心知識點,如果有不清楚的朋友可以看看這篇文章:5 無向圖切圖對於無向圖的切圖,我們的目標是將圖切成相互沒有
DBSCANKdtreeCluster ec
本篇論文采用的方法是以第38個鐳射發射器作為基準,根據每個鐳射發射器的水平偏移角度來計算最相鄰、最平行的上下兩個點,算出來之後,把這個關係用表儲存下來,以後每次使用的時間直接查表(但是這裡有一個疑問,論文裡面計算列的最平行的關係的時候,還有

”的問題最好就舉個例子講個故事吧~探討:在面試過程中你可能會不自覺進入一些問題“圈套”,這是面試官想深入瞭解當你遇到技術難題中你看重哪些資訊,希望看到你如何處理這個問題以及你解決問題的主要方法,這時一定要就你的思維過程進行討論
count()[‘total_point’]等頻分箱df[‘point_bins_f’]=pd

——採用“單因素方差分析”聚類分析除了對類別的確定需討論外,還有一個比較關鍵的問題就是分類變數到底對聚類有沒有作用有沒有貢獻,如果有個別變量對分類沒有作用的話,應該剔除

此外,作者還引入了聚類注意機制來對個體進行分組,並利用組內和組間的關係獲得更好的群體特徵表示