
我們將這兩個表匯入到查詢中:想要在人員資訊表中增加入職日期資訊,那麼要先選中人員資訊表,然後再選擇匹配表,將兩個表中的ID列分別選中,如下圖點選確定,得到以下結果可以看到增加了一個新列,展開選擇擴充套件入職日期:確定之後選擇關閉並上載,就可
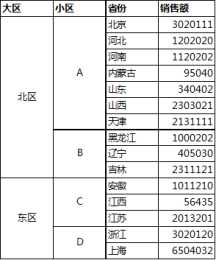
點選“開始-關閉並上載”這樣,我們就單獨生成了一個脫離資料來源的可供排序的檔案本方法使用了Power Query的填充功能
對於query和doc則各自得到intra-pooling,一共有5個attention,每個attention可以得到原始向量與attention互動後的向量,透過concat、哈達碼積和minus後,經過壓縮函式進入下一層(4) 前面5
因此,在刻畫單詞與文件相似性時,BM25是這樣設計的:其中,是單詞t在文件d中的詞頻,是文件d的長度,是所有文件的平均長度,變數是一個正的引數,用來標準化文章詞頻的範圍,當,就是一個二元模型(binary model)(沒有詞頻),一個更大

即使影象只是畫素、濾鏡或尺寸不同,也可以利用雜湊演算法檢測出來煉丹師小王利用 Jina Hub ImageHasher Executor,終於解決了資料集中的相似影象問題,並將程式碼都放到了 Colab 上,參與更多深度學習、雜湊演算法相關

zeros(N)foriinrange(N):s[i]=score_attention(method,query_data,input_data[:,[i]])s/=torch

隨機初始化特定類別部分引數,利用新類上的k-shot樣本進行訓練,假設訓練後的特定類別部分引數為利用權重預測的元模型將轉為將Faster RCNN中類別無關部分引數設定為,特定類別部分引數設定為,共同組合成最終應用於新類的目標檢測模型到這裡

接下來,Tony老師會開一系列課程,教大家如何使用Power BI,如果你有興趣學Power BI,歡迎加入QQ群,共同探討:282308215我們以一個實際案例來學習如何抓取網頁資料:統計過去一個月上海的天氣情況
why self-attentionself-attention是兩個矩陣做內積,有d個計算複雜度就是n^2*d,且沒有時序資訊,矩陣內積可並行,所以時序計算複雜度就是常數,在進行內積時,一個query和所有key都進行求權重,所以最大路長

QAngaroo-WIKIHOP 資料集示例本模型有兩個創新點:雙向注意力學習query-aware representation多級特徵得到節點間關係表示ModelBAG 模型結構圖BAG 模型包含5個部分:實體圖結構(entity gr

語言模型,語言模型會給每一個 query 計算出困惑度,表示一個 query 合法的程度,ASR 模組,提供一些語音方面的特徵,包括使用者說話的語速、信噪比,包括音量等,ASR 可以對 query 提供置信度資訊,置信度表徵的是語音清晰的程
二、基於多模型融合的詞權重計算TF-IDF計算詞權重方法簡單可靠,但真正應用到系統中其準確度還是遠遠達不到要求,基於搜尋使用者的點選資料,提出一種離線資料探勘結合機器學習計算詞權重的方法,並在實際的應用中獲得不錯的效果,其實現框圖如下:詞權
, VLDB2017, The Complete Story of Joins, BTW2018, Adaptive Optimization of Very Large Join Queries, SIGMOD執行器2011, Effic
3.5 PANet創新點:利用了prototypes上的度量學習,無引數提出prototypes對齊正則化,充分利用support的知識對於帶有弱註釋的少樣本直接使用用同一個backbone來提取support和query的深度特徵,然後使
4 總結和展望query生成/推薦基本是Sequence to sequence和向量相似召回兩個思路,主流的RNN/CNN方法當時還是因為效能問題在應用上有點阻礙,所以我們嘗試了一些在效果上不輸於lstm但是非常簡潔的方法,這些方法在效能

這兩個資料集包含有共同生物狀態的細胞,但query資料集也包含有獨特的總體(黑色表示)(B) 我們進行典型相關分析,然後對典型相關向量作L2標準化,將兩個資料集投影到共有的相關結構的低維子空間
歌來源有爬取的也有合作的,進入知識庫後會有一個文字搜素,抽取feature,利用learn to rank排序,透過query確定使用者想聽那首歌,確定歌名,抽取slot,利用GBDT模型打分

),甚至不需要做physical designmulti-cluster + shared data計算儲存分離,各自獨立擴充套件傳統的share nothing數倉架構存在一些問題:資料和計算耦合,所有的機器是同構的,但workload卻

為了使資料更加適合程式碼搜尋任務,GitHub 團隊執行了一系列預處理步驟:文件 d_i 被截斷,僅保留第一個完整段落,以使文件長度匹配搜尋 query,並刪除對函式引數和返回值的深入討論

查詢的執行因為 F1 Query 強調的是跨機房部署,因此查詢的請求跟實際的資料很可能不在一個集群裡面,當請求到達一臺 F1 Server的時候,它首先對查詢進行解析,看看查詢裡面涉及哪些資料來源,如果有任何資料來源不在這個資料中心裡面,