
最後,作者累加了所有模態下最後一個GNN層的輸出,作為user或item最終的表示,預測user-item pair的話,使用二者點乘形式進行預測,
CLIPpaper | code1、CV資料集標註成本太高2、當前模型只能勝任一個任務,遷移能力差3、當前模型泛化性、魯棒性較差1、利用web上大量的圖文對,是天然存在的資料2、web上的資料量大,差異也大,訓練可以得到泛化能力強的模型,容

1可程式設計映象有效模態G5200區域性座標系設定非模態G5300選擇機床座標系非模態G5414工件座標系1選擇模態G55工件座標系2選擇模態G56工件座標系3選擇模態G57工件座標系4選擇模態G58工件座標系5選擇模態G59工件座標系6選

強化學習聚焦於智慧體與環境的互動,這是AGI意識誕生與具身化的必由之路

▲ MORE資料集的統計資料基準模型:▲ 圖2 ExMore的完整架構結論總之,印度因陀羅普羅司泰資訊科技研究所的學者提出了一種新的多模態諷刺解釋(MuSE)的任務,旨在透過標題和影象來展開多媒體帖子中的預期諷刺

具體來說,三者的串聯關係如下圖所示:圖5 LAPO元件關係圖在這個policy iteration的流程中,policy evaluation時Q函式的更新方法如下:然而需要注意的是,由於隱變數將用作動作策略的輸入,因此一個無界的可能導致動
而在多模態翻譯任務中,我們給模型不僅有源語言,還有輸入的內容相關的圖片,輸出就是目標語言,比如同樣是英文翻譯成中文的任務中,多模態翻譯任務的輸入是:I love China

本文提出的具體方法參考下面這張圖:首先,模型針對音訊和影片模態,都有一個各自的身份編碼器,和語言編碼器

同一個圖片/文字不同視角的表示應當是相似的,ITC的這個思想就是經典的單模態對比學習,與SimCLR[3],MOCO[4],SimCSE[5]相似

肯定的判斷,謂詞是肯定的,a是b,例如我是中國人

前言一、待求構件兩端加軸力確定其計算長度這個方法經常被一些結構師應用於實際專案中,原因是有時某根柱比較特殊(例如越層柱),設計師只想求出此柱的計算長度,進行整體屈曲分析比較耗時,並且認為整體屈曲模態眾多難以判斷採用哪階屈曲,為了簡化起見,採
然而,因為採用單個模態的低階特徵而非translation方式,故非常容易被輸入噪聲和缺失資訊所影響2. 基於轉移的受機器翻譯中的sequence to sequence的成功的啟發,最近的研究提出了多模態融合模型,思路是將一種模態向另一種
案例:賓士新S級搭載的MBUX系統結合了觸控操作,手勢識別,人臉識別,語音助理Vr領域應用眼部追蹤提供沉浸式體驗人工智慧基於多模態實現情感計算,進行情緒感知

FLAVA基於三種不同的輸入:匹配的圖片-文字單獨文字單獨圖片解決三個領域的問題:NLP:語言理解(如GLUE)CV:視覺識別(如ImageNet)多模態:多模態解釋(如VQA)圖片編碼器(Image Encoder)FLAVA直接借用既有
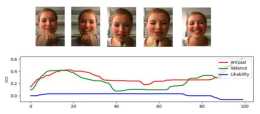
這兩種融合模式在我們的工作Video Emotion Recognition in the Wild Based on Fusion of Multimodal Features [10](圖6)和Speech Emotion Recogn
作者為同一人常規的attention map是對單個特徵的attention:output=feature * attention map,而本文提出的bilinear attention map則對兩個特徵的attention:outpu
在POM模式中,內模態的時間步長通常是外模態的數十倍
必然非p>可能非p(例如,火星上必然沒有生物

0版本增加acoustics modal模組,不需要聲學外掛就可以計算,賦予各部分真實材料,指定流體域與固體域,他將自動生成流固耦合面

PET/CT - MR 多模態融合技術檢查介紹PET/CT - MR 多模態融合技術是基於 PET/CT 和 MR 成像的一種異機融合技術,是在 PET/CT 全身檢查的基礎上,進一步利用 PET/CT 所產生的 PET 影象與區域性 MR