
#分庫分表前分庫分表後併發支撐情況MySQL 單機部署,扛不住高併發MySQL 從單機到多機,能承受的併發增加了多倍磁碟使用情況MySQL 單機磁碟容量幾乎撐滿拆分為多個庫,資料庫伺服器磁碟使用率大大降低SQL 執行效能單表資料量太大,SQ

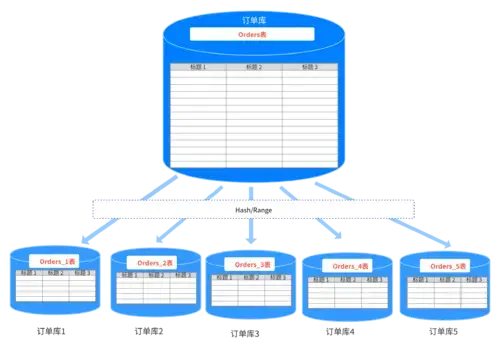
================線上京東地址點選這裡===============二、分庫分表水平分庫概念:以欄位為依據,按照一定策略(hash、range等),將一個庫中的資料拆分到多個庫中
2 記錄一次異構具有複雜分片規則資料庫的過程文章集中整理總結mysql分庫分表開源產品,分散式資料庫的設計,以及實際應用案例等相關內容,部分附上本文作者實際應用過程中的理解
SqlServer,//資料庫型別IsAutoCloseConnection = true //不設成true要手動close})4|0分表既然是分表,那就大膽認為他是操作【單機資料庫】,只需要對實體類進行動態對映表名即可實現,SqlSug
(TOP我們可以解析為這三個操作的組合上,暫不考慮)正常來說,我們應該把所有的子句在各個分表上都執行一遍然後再聚合,但是ANSI SQL眉頭一皺,發現事情沒有那麼簡單:正常聚合即可的操作組合groupbyagroupbyaorderbybg
下圖演示了一個數據庫表(user表)在分庫分表情況下,資料庫中介軟體內部是如何執行一個批次插入sql的:資料庫中介軟體主要對應用遮蔽了以下過程:sql解析:首先對sql進行解析,得到抽象語法樹,從語法樹中得到一些關鍵sql資訊sql路由:s
二、寫與事務這裡說的寫是命中資料之後的寫操作效能討論鎖的方式:不建議你直接在資料庫層面使用悲觀鎖,這樣帶來的效能損壞是極大的,因為明顯這樣會導致被你鎖住的資料只能苦等

要想做到資料的水平切分,在每一個表中都要有相冗餘字元作為切分依據和標記欄位,通常的應用中我們選用id作為區分欄位,基於此就有如下三種分庫或者分表的方式和規則:(當然還可以有其他的方式)(1)號段分割槽id為1~1000的對應DB1,1001

1/60度)1分表的公式規定用 V = 1/ a 表示視力,其中 a 表示在標準檢查距離( 5m 或 6m) 處, 視標一劃在眼節點形成的視角( 分) 記錄
基本忘了SQL,補充個思路,where的條件順序影響查詢速度看具體的sql直譯器是怎樣的了,題主沒說但一般對於後面那個條件:and 1=1 一般直譯器是忽略的那就剩a=‘a’具體看在a欄位上的可選擇性:如果a欄位資料密度不大,可選擇性好,值

(1)跨庫關聯查詢在單庫未拆分表之前,我們可以很方便使用 join 操作關聯多張表查詢資料,但是經過分庫分表後兩張表可能都不在一個數據庫中,如何使用 join 呢