基於R語言的信用卡逾期邏輯迴歸模型
資料來源
採用某銀行30000客戶的信用卡消費情況。
讀取資料來源:
data <- read。csv(file = ‘E:\\data\\Credit_Card。csv’,header = T)
head(data)

檢視資料集中個欄位的表現情況:
summary(data)

資料字典

資料處理
由資料彙總中可以看到, MARRIAGE欄位含有其他狀態0的狀態,使用table(data$MARRIAGE)檢視MARRIAGE值分佈情況。
MARRIAGE 0 1 2 3
數量 54 13659 15964 323
0的婚姻狀態不多,不能代表任何狀態,可以把MARRIAGE為0的狀態歸到3(其他)中。
類似地EDUCATION欄位0,4,5,6都是其他的教育等級,也可以考慮都歸為一類4或者0;程式碼如下:
data1 <- data%>%
mutate(EDUCATION=ifelse(EDUCATION==0 | EDUCATION==4 | EDUCATION==5 | EDUCATION==6 ,4,EDUCATION),
MARRIAGE=ifelse(MARRIAGE==0,3,MARRIAGE))
單變數分析

從年齡分佈圖中可以看出,年齡分佈大致上呈現為正態分佈,且在25-35歲之間人數最多。
性別分佈情況

從性別看出在本案例中女性比男性多
學歷分佈情況

從圖中看出,大學及以上學歷的人佔本案例人數80%以上,說明信用卡使用者文化水平較高。
婚姻分佈情況

從婚姻分佈情況可以看出,單身漢或許更加習慣使用信用卡。
單變數分析程式碼
hist(data1$AGE,main = “Customer age distribution”,freq=FALSE)
lines(density(data1$AGE),col=‘red’)
rug(jitter(data1$AGE))
SEX <- table(data1$SEX)
label <- round(SEX/length(data1$SEX)*100,2)
label2 <- c(“Male”,“Female”)
pie(SEX,labels = paste(label2,“ ”,label,“%”,sep=‘’),main = “性別分佈情況”)
EDUCATION <- table(data1$EDUCATION)
EDUCATION <- sort(EDUCATION,decreasing = T)
label <- round(EDUCATION/length(data1$EDUCATION)*100,2)
label2 <-c(“university”,“graduate school”,“high school”,“others” )
pie(EDUCATION,labels = paste(label2,“ ”,label,“%”,sep=‘’),main = “學歷分佈情況”)
MARRIAGE <- table(data1$MARRIAGE)
MARRIAGE <- sort(MARRIAGE,decreasing = T)
label <- round(MARRIAGE/length(data1$EDUCATION)*100,2)
label2 <-c(“single”,“married”,“others”)
pie(MARRIAGE,labels = paste(label2,“ ”,label,“%”,sep=‘’),main = “婚姻分佈情況”)
逾期情況
正常 逾期
合計 23364 6636
佔比 77。88% 22。12%
多變數分析
性別和年齡的關係圖
ggplot(data=data1, aes(x=SEX,y=AGE))+geom_boxplot(aes(fill=as。factor(SEX)))

由圖可以看出在使用該信用卡上,女性比男性更為年輕化一點。

在各個信用額度區間,男女人數分佈相差不大。
ggplot(data=data1, aes(x=EDUCATION,y= LIMIT_BAL))+geom_boxplot(aes(fill=as。factor(EDUCATION)))

從學歷和信用額度上看,除去4類其他的教育等級外,1-3的教育等級各個信用額度在普遍下降,可以說明教育程度和信用額度成正比關係。
婚姻狀態和信用額度的分佈關係
ggplot(data=data1, aes(x=MARRIAGE,y= LIMIT_BAL))+geom_boxplot(aes(fill=as。factor(MARRIAGE)))

同樣地,婚姻狀態為1的(已婚)比單身和其他狀態人的信用額度普遍要高。
建模
將資料分成訓練集和測試集;訓練集隨機抽取70%的資料,測試集為剩下30%的資料。
使用訓練集進行建模,首先是使用全部變數進行建模,得到的模型結果如下圖所示,執行程式碼為:
set。seed(1234)
training_data_size <- floor(0。7* nrow(data1))
training_data_size
creditcard_train_index <- sample(1:nrow(data1), training_data_size)
#Training data
creditcard_train <- data1[creditcard_train_index, ]
# head(creditcard_train)
# Testing data
creditcard_test <- data1[-creditcard_train_index, ]
creditcard_model <-glm(default。payment。next。month ~ 。,
family=binomial(link=“logit”),data=creditcard_train)
summary(creditcard_model)

由圖中可以看出可以透過p值檢驗的引數有:LIMIT_BAL、SEX 、EDUCATION、MARRIAGE 、
AGE 、PAY_0 、PAY_2、PAY_3、BILL_AMT1、PAY_AMT1 、PAY_AMT2;
然後再利用這些透過p值檢驗的引數重新建立模型,得到的結果如下圖所示:

程式碼如下:
creditcard_model1 <-glm(default。payment。next。month ~ LIMIT_BAL+SEX + EDUCATION + MARRIAGE +
AGE + PAY_0 + PAY_2 +PAY_3+ BILL_AMT1 +
PAY_AMT1 + PAY_AMT2 ,
family=binomial(link=“logit”),data=creditcard_train)
summary(creditcard_model1)
模型評估
利用測試集對模型進行評估,我們設定當預測值大於0。5時,則認為是信用卡逾期,否則為正常。程式碼如下:
predicted_values <- predict(creditcard_model1, type = “response”, newdata = creditcard_test)
creditcard_test$predicted_values <- predicted_values
creditcard_test$prediction <- creditcard_test$predicted_values >0。5
creditcard_test$prediction <- as。numeric(creditcard_test$prediction)
depvar <- creditcard_test$default。payment。next。month
indepvar <- creditcard_test$prediction
t <- addmargins(table(depvar, indepvar))
得到的誤分類矩陣如下表所示:
實際 預測
0 1 合計
0 6805 187 6992
1 1531 477 2008
合計 8336 664 9000
模型的準確率=(6805+477)/9000=80。91%
模型的召回率=477/2008=23。75%
(從上面的指標中可以看出模型雖然準確率較高,但是召回率的值不大,模型的效果不是很理想)
模型Roc曲線
程式碼如下:
library(pROC)
modelroc <- roc(creditcard_test$default。payment。next。month,predicted_values)
plot(modelroc, print。auc=TRUE, auc。polygon=TRUE,legacy。axes=TRUE, grid=c(0。1, 0。2),
grid。col=c(“green”, “red”), max。auc。polygon=TRUE,
auc。polygon。col=“skyblue”, print。thres=TRUE)

可以看出模型的AUC值為0。717,可知模型的結果不是很理想。
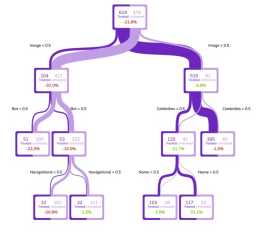
由於模型效果並不理想,所以需要改變模型引數或者使用其他的模型進行模擬(例如決策樹、神經網路等),看最終哪個模型更加適合這個資料集。