地點在北京,一個居民市場,我們的產品是純粗糧很健康口感也很“勁道”,如果可以的話想送到一些飯店做渠道供應
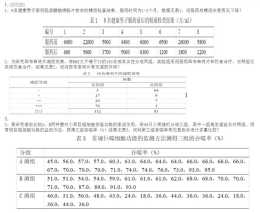
二,(1)建立檢驗假設,確定檢驗水準H₀:有或無服用西布曲明片成年女性減肥效果的總體分佈相同

而抽樣檢驗的活動的必須進行抽樣過程,抽樣是一種系統的統計方法,它透過研究總體有代表性的部分(即樣本)來獲取該總體的某些特性資訊
所以,總體與樣本的引數其最大的差別不是計算公式(考慮自由度的方差依然是無偏的),而是其含義和計算的邏輯,理解這些,比單純記住公式和表現形式有意思也有意義多了
除此,目前正在興建石衡滄港城際高鐵,長期看還有保滄(經過雄安新區)、津滄等城際計劃,這些鐵路開通後,滄州的交通更加四通八達

我們第一篇講了跨專業心理學考研如何規劃自己的心理統計複習計劃,接下來我們講一個很多人都不清楚的點,那就是拿到一道題我們該如何入手去解決這道題,如何從題目中獲取有效資訊其實我們的教材和教輔上都有提到解題的步驟,例如區間估計的步驟:假設檢驗的步
具體做法如下:設總體的分佈函式形式已知,其中含有一個未知引數,首先從總體中抽取樣本,然後按照一定的方法構造合適的統計量作為的統計量,記為,代入樣本觀測值,即得到的估計值
2014年年末-2018年年中,我都是在網際網路金融公司中工作,所以對p2p平臺還算了解些
在多次查閱各種資料後,找到了一個講的最粗暴的,最淺顯易懂的:舉個例子,全國成年男性的身高是一個總體,我們想知道身高的標準差
大致是如果總體的分佈函式的引數可以用總體的矩顯式表達出來,那麼就可以藉助這個顯式表示式,把總體的矩用樣本的矩替換掉,來得到一個統計量
高中淄博十七中,自小沒幹過活,從小嬌聲慣養胡作非為,高中一直在家吃,偶爾收同學飯票,總體來說早餐六塊,午餐10塊,因為晚上練體育所以沒怎麼吃過晚飯,沒事時常回家吃,總體來說一個月500多吧,淄博總體來說消費水平比較低,600多就比較富裕了目

機率抽樣方法1: 簡單隨機抽樣所有調查物件編號,透過隨機數進行抽樣選取,適用於研究總體不太大或者總體單元的元素有完備名單的時候使用
關於總體、樣本、統計量相關的內容,就先介紹到這
我一直都比較喜歡SUV,買車比較看重外觀,這款車顏值太高了,很搶眼,其次配置也很重要,這車有手機藍芽鑰匙、語音助手、遠端車輛控制等,很有科技感開了這一個月下來,個人覺得天際ME5總體表現還是不錯的

抽取的樣本數量要足夠多 > 30%樣本數量:有多少個樣本樣本大小:每個樣本里有多少個數據抽樣分佈:樣本平均值的分佈視覺化eg:焦點小組隨機抽樣應用:抽獎隨機抽樣應用#匯入random(隨機數)模組importrandom‘’‘使用ra
xm是來自正態總體N(μ,δ2)的樣本,在總體方差已知的情況下,如果需要對總體的均值進行檢驗,就可以假設H0: μ=μ0,H1: μ≠μ0,此檢驗可以使用的檢驗統計量為例如,一個由50名學生組成的樣本其平均身高為174
因此我認為學習“三大分佈”應關注:統計量的構成密度函式及影象特點與正態總體的聯絡(重要性質)(1)卡方分佈統計量設獨立同分佈於, 則為卡方分佈的統計量,它是n個標準正態分佈隨機變數的平方和

總體的標準差的平方,但是當我們用樣本來估計總體標準差時,因為抽取的樣本大小對於總體而言很小,所以算出的標準誤差的值會比總體的標準差偏小,所以我們對樣本去估計總體的標準差公式給出如下表達:注:如果只是想討論樣本中資料的波動大小,那麼利用每個數

此類物件我們將其稱作總體或母體(population),另一類物件則是我們在城市中遇到的市民們,他們雖然不能組成全體市民,但是他們每一位同志都在城市生活,滿足我們想要了解物件的所有條件,這些我們接觸過的市民全體,可被稱作樣本(sample)
與此道理一樣,那些精通文章要術的作者,往往為了追求短小精悍,其著述通常不會太長,而像知識才氣匱乏的作者,卻是因為無法展開長篇大論,而其文章也會十分簡短