決策樹:機率,熵,Gini係數,KNN演算法:距離函式K-Means演算法:距離函式主成分分析:協方差矩陣,散佈矩陣,拉格朗日乘法,特徵值與特徵向量線性判別分析:散佈矩陣,逆矩陣,拉格朗日乘法,特徵值與特徵向量流形學習:流形,最最佳化,測地
減小方差的方法是引入值函式近似,這樣做使得增量式地更新accumulate reward的估計,而不是直接使用當輪取樣得到的平均值(最後有一個簡單直觀的例子

大數定律基本上就是說滿足一定條件,則均值依機率收斂到均值的期望,所以可以用大量資料的均值近似代表期望,而樣本滿足iid(獨立同分布),所以當時,均值=期望=均值的期望均值:多個隨機變數的和再除以個數,相當於還是一個隨機變數(實際操作相對於抽

離散機率分佈包括:伯努利分佈、二項分佈、幾何分佈、泊松分佈連續機率分佈包括:正態分佈、冪律分佈——————————————————————————————————在python的科學計算包scipy的stats模組計算出常見機率分佈的機率值

全域性馬爾可夫性什麼樣的分佈可以由無向圖來表示變數之間的獨立性關係
邊際分佈函式設F(x,y)是二維隨機變數(X,Y)的分佈函式,X和Y的各自隨機變數的分佈函式為:條件分佈設二維隨機變數(X,Y), 在條件下的機率為:若存在密度機率函式,則其密度機率函式為:邊際密度函式則有下式得到:隨機變數的矩一個連續的隨
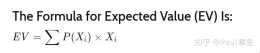
瞭解預期值 情景分析是計算投資機會的預期價值(EV)的一種技術

4月3號的狀態分佈矩陣 S3 = S2 * P (看見沒,跟S1無關,只跟S2有關)

因為只有將其變成實數集,我們接下來才能引入函式這個數學工具到考研機率論中,函式是定義在數集上的對映,否則我們只能使用古典機率這種在考研範圍內比較簡陋的數學工具了

兩個樣本的容量都很小[1]第一個假設條件,如果總體服從正態分佈,那麼在和已知的情況下,樣本均值也服從正態分佈:顯然,根據“獨立正態隨機變數的線性組合仍然服從正態分佈”這條性質,這兩樣本均值之差也服從正態分佈:那麼,化為標準正態,則為:特別,

方差 (二階中心矩)隨機變數的方差定義為其二階中心矩:歸一化矩歸一化矩是無量綱值,表示獨立於任何尺度的線性變化的分佈,歸一化階中心矩或者說標準矩,是階中心矩除以標準差,歸一化階中心矩為偏態 (三階中心距)隨機變數的偏態(衡量分佈不對稱性)定
F分佈有性質=__________________設,是來自總體的樣本,均值為,樣本方差為,則:________________________________________________________________________
θ)的表達,對於這個機率表示式一直理解的不清楚,於是在網上查閱資料,整理如下:我們先來逐個分析裡面的每一個變數
由此可以看出,獨立性反應了已知X的情況下,Y的分佈是否會改變,或者說,在給定隨機變數X之後,能否為Y帶來額外的資訊

工學門類的材料與工程,化學工程與技術,地質資源與地質工程,礦業工程,石油與天然氣工程,環境科學與工程等一級學科中對數學要求較高的二級學科,專業

但兩個任意正態隨機變數的平方和服從何種分佈呢

事實上,以上計算過程等價於總結:機器學習中協方差矩陣的快速計算公式為:其中,為樣本個數,為大量樣本拼成的維矩陣

不知道為什麼前面兩節的程式碼無法顯示,如果需要看的話可以到我公眾號上看隨機事件與機率古典概型定義隨機分配(佔位)簡單隨機抽樣幾何概型重要公式一維隨機變數及其分佈隨機變數與分佈函式離散型隨機變數連續型隨機變數X~F(x)八個常見分佈多元隨機變

而在CLIP-Lite中作者提出用JS下界去替代CLIP中的infoNCE下界,而JS下界不依賴於負樣本數量,因此每個正樣本至多隻需要一個負樣本就可以進行下界最佳化,如Fig 1

瞭解了協方差的一些基本內容後,我們再回過頭來看看之前學過的方差:我們已經瞭解方差性質1:透過協方差,我們可以進一步得到方差的計算公式:推廣到多個變數的情況:在現實中,的數量級很有可能不同,比如X代表體重(單位:千克),Y代表身高(單位:米)