
b) 從候選集獲取關鍵詞首先快速用無監督演算法建立一個baseline,由於我們用於提取關鍵詞的文字比較短,因此基於圖的TextRank以及聚類的方法都不適合,效果並不好,TFIDF達到了最好的基線效果

比如剛才我們確定了r8上有3和6,所以r8結構涉及的區域單元格的候選數3和6均可以被刪除
將所有需要計算支援度的項集,也就是書中的15個“候選3項集”建三叉樹
首先,提出 Multi-length-input dilated causal Convolutional Neural Network (Mdc-CNN),它將不同長度和不同變數的shapelet候選嵌入到一個統一的空間中(shapele

// Retrive keyframes connected to the current keyframe and compute corrected Sim3 pose by propagation// 得到Sim3最佳化後,與當前幀相
其實就是多觀察多試吧,所謂技巧不過是提前知道這種形式下某種填法最後會行不通以第二張圖來說,如果1行7列為8,則6行5列為8,此時第2宮無8可填我喜歡的方法是,找到兩個空,這兩個空不是填ab就是ba,然後蒙一個,比如選ab吧,然後繼續往下推一

影象分類,目標檢測與例項分割的對比目前主流的目標檢測演算法主要是基於深度學習模型,其可以分成兩大類:(1)two-stage檢測演算法,其將檢測問題劃分為兩個階段,首先產生候選區域(region proposals),然後對候選區域分類(一

深度學習相關的目標檢測方法也可以大致分為兩派:基於候選區域的,如R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN

R為關係的名字,A1是屬性,D1是屬性所對應的域,n是關係的度或目,關係中元組的數目成為關係的基數

// Retrive keyframes connected to the current keyframe and compute corrected Sim3 pose by propagation// 得到Sim3最佳化後,與當前幀相
關係R中的一個屬性組,他不是R的候選碼,但它與另一個關係的候選碼相對應,則稱這個屬性組為R的外碼/外來鍵兩個關係通常透過外碼相互連線關於碼的概念是關係資料庫的基礎,在人民大學王珊,薩師煊教授主持編寫,高等教育出版社出版的,《資料庫系統概論》
然而,家裡的中央空調聲音卻有點(hen)大(chao),關鍵是開到32度也不熱,由於怕吵,我就索性關掉了,只好默默縮排十層棉被裡~~訴求:不奢望像大北京室溫23度穿個短袖隨便走,也折騰不起把地板全部敲掉鋪成地暖,就算鋪了也燒不起
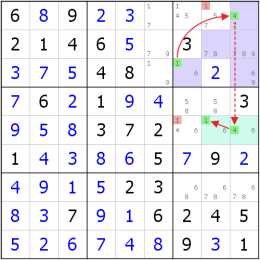
我們把r1c78看作一組ALS(兩個單元格,2、4、7三種候選數),根據強關係第二定義,當r1c78(7)和r1c7(4)同時為假時,r1c78之中只剩下2一種候選數,填入r1c78兩個單元格之中很明顯是會矛盾的,所以r1c78(7)和r1

北京時間10月22日凌晨,《法國足球》正式公佈2019年金球獎30人候選名單,在第4批名單當中,效力熱刺的韓國巨星孫興慜榜上有名,這是他職業生涯首次入選金球獎30人大名單
退化魚當綠色和粉色作為魚身體,藍色作為魚鰭的時候,可以刪掉的候選數是黃色標記的那個候選數

參考:程式碼連結:(7)SPCNet曠視科技:一種任意形狀的場景文字檢測演算法(8)【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and
一朋友們請看,先找到兩個紅色框中的跨區數對(79),數對內兩個候選數79之間是強鏈相連,而且是空矩形的粉色強鏈,沒有弱鏈的性質,不可以當弱鏈使用
global方式需要更多的候選點,即對候選點提取數量比local更多,因為沒有像local方式一樣每次節點劃分時,對當前節點的樣本進行細化,local方式更適合樹深度較大的情況

而個性化的資訊其實就包含在使用者過往的行為裡,因此很多模型嘗試透過引入使用者的行為序列進行建模,來學習到使用者當前的興趣表示,再透過使用者興趣表示跟候選目標item的作用來評估候選item是否符合使用者當前的興趣

最終候選點位置接下來是候選點與標註點之間的一對一匹配,本文提出了對任意兩點間匹配的成本公式:p 為點的位置,c 為後續點預測置信程度當候選點預測置信程度越大時,其被匹配的成本得到相應縮小