
典型場景三:上游關注執行結果,但執行時間很長有時候上游需要關注執行結果,但執行結果時間很長(典型的是呼叫離線處理,或者跨公網呼叫),也經常使用回撥閘道器+MQ來解耦
![MQ矽樹脂線上粘度是什麼,看完你就知道了[今日更新]](https://img.heatask.com/upload/thumbnail/XHQ0W8nJVM8SxApyrIk-NV07WWBJYS9b8i0lwBi2LXCvo4DmW_LcCSz0CmllVzQMWjLzEuQUW7+HwqnirrklCUttN.jpeg)
MQ矽樹脂的效能及其應用範圍主要取決於其合成工藝條件和分子中有機基團的型別、數量,即M鏈節和Q鏈節的數量比

如果使用 MQ,那麼 A 系統連續傳送 3 條訊息到 MQ 佇列中,假如耗時 5ms,A 系統從接受一個請求到返回響應給使用者,總時長是 3 + 5 = 8ms,對於使用者而言,其實感覺上就是點個按鈕,8ms 以後就直接返回了,爽
現在記錄如下:遠端SQL server資料庫:將裝置的測試資料直接傳輸到客戶的MES工程師已經給建好的遠端SQL server資料庫中:LabVIEW遠端sql server資料庫通訊上圖所示為實際中的LabVIEW程式碼
}public SendResult sendMessage(final String addr,final String brokerName,final Message msg,final SendMessageRequestHeade
單執行緒的模式去消費建議不再mq當中使用訊息的投遞順序來保證訊息的順序一致性,因為訊息中介軟體是公用的,保證一致性需要確認,我們只需要保證訊息投遞的準確性,有業務來做訊息的順序處理,對於kafka如果要保證訊息的一致性,必須每一個topic
學技術最好的方式是能夠找到這一行的頂尖高手,和他們交流,他們會把他們最好的經驗分享給你,一定是他經過長期實踐總結的,一定是大道至簡的,就像非同步的本質有人這麼定義它嗎(沒有自稱高手的意思,我一直以“IT小學生”自居)
3. 接收訊息執行緒接收訊息的函式介面如下,rt_err_t rt_mq_recv(rt_mq_t mq, void *buffer,rt_size_t size, rt_int32_t timeout)引數mq為訊息佇列物件的控制代碼
已有方案及痛點位元組跳動內已有解決方案如下圖所示,主要分了兩個步驟:透過 Dump 服務將 MQ 的資料寫入到 HDFS 檔案再透過 Batch ETL 將 HDFS 資料匯入到 Hive 中,並新增 Hive 分割槽痛點任務鏈較長,原始資

時效性:ms級可用性:非常高,分散式架構訊息可靠性:經過引數最佳化配置,訊息可以做到0丟失功能支援:MQ功能較為完善,還是分散式的,擴充套件性好總結:介面簡單易用,可以做到大規模吞吐,效能也非常好,分散式擴充套件也很方便,社群維護還可以,可
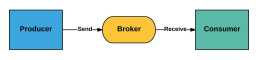
四、訊息佇列的應用場景1.非同步處理訊息佇列的主要特點是非同步處理,主要目的是減少請求響應時間,實現非核心流程非同步化,提高系統響應效能

transaction = false# mq configcanal

3 快取高併發場景,大多讀多寫少,可以在資料庫和快取裡都寫一份,然後讀時大量走快取
075聯合作戰演練(圖源:西葛西造艦軍事CG)大伊萬認為,中國海軍“兩攻”上的無人直升機,所承擔的任務也就是這三項:第一是海上巡邏與輔助性的航空制海,第二是戰場偵察與監視以及中繼通訊,第三可能還會出一個用於配備給055和052D的版本用來給
實際的過程是——請求資料先發到 mq ,應用程式監聽mq 並消費訊息
在把任務(自動化)/ 意志(人類)的區別轉換為可供討論的有用的模型中,下圖為技術進步和作戰概念如何能決定未來的空軍 MQ-9 無人機編隊提出了代表一種可能,或可以說理想的觀念
系統C呼叫系統D,一般耗時2s使用者一個請求過來巨慢無比,就像走過長長的套路一樣因為走完一個鏈路,需要耗費:20ms + 200ms + 2000ms(2s) = 2220ms,也就是2秒多的時間