系統設計那些事兒:硬碟 IO
資料庫系統總會涉及非易失性儲存,我們需要知道一個典型的計算機系統是如何進行儲存管理的。時至今日,雖然 SSD 已經成為很多資料庫管理員的選擇,但傳統 HDD 還是有著廣泛的應用,檔案系統和儲存引擎大部分設計和發展還是基於 HDD 的行為;過去數十年來,HDD 一直是計算機系統中持久儲存的主要形式。
本文回顧硬碟的物理特性,硬碟的主要效能指標,以及操作是如何進行硬碟 I/O 效能最佳化的,最後參考開源系統來討論如何根據硬碟特性進行系統設計。
硬碟的物理特性
硬碟(Hard Disk Drive,HDD,有時為了與固態硬碟相區分稱“機械硬碟”)是計算機最基礎的
非易失性儲存
,它在平整的磁性表面儲存和檢索資料,資料透過離磁性表面很近的磁頭由電磁流來
改變極性的方式
被寫入到磁碟上。資料可以透過碟片被讀取,原理是磁頭經過碟片的上方時碟片本身的磁場導致讀取線圈中電氣訊號改變
[1]
。
硬碟主要包括一至數片高速轉動的碟片(platter)以及放在傳動手臂上的讀寫磁頭(read–write head),每個碟片都有兩面,都可記錄資訊,因此也會相對應每個碟片有 2 個磁頭。物理結構如下圖所示:

我們通常更關注硬碟內部的結構:

圖源自《資料庫系統概念》
磁軌(Track)
:當硬碟旋轉時,磁頭若保持在一個位置上,則每個磁頭都會在磁碟表面劃出一個圓形軌跡,這些圓形軌跡就叫做磁軌;
柱面(Cylinder)
:在有多個碟片構成的盤組中,由不同碟片的面,但處於同一半徑圓的多個磁軌組成的一個圓柱面;
扇區(Sector)
:磁碟上的每個磁軌被等分為若干個弧段,這些弧段便是硬碟的扇區(Sector)。硬碟的第一個扇區,叫做引導扇區;
硬碟效能的度量
硬碟常規的一次 I/O 需要 3 步,每一步都有相關的延遲,可以將 I/O 訪問時間(access time)表示為 3 部分之和:
尋道時間(seek time):將讀寫磁頭組合定位在訪問塊所在磁軌的柱面上所需要的時間;
旋轉延遲(rotational latency):等待訪問塊的第一個扇區旋轉到磁頭下的時間;
傳輸時間(transfer time):完成資料傳輸需要的時間,取決於硬碟資料傳輸率;
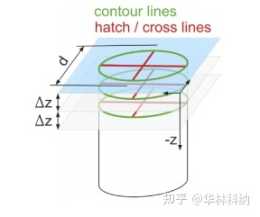
為了更好理解尋道時間和旋轉延遲,可以參考下圖:

值得一提的是,硬碟的趨勢是傳輸速率相當快,因為硬碟製造商擅長將更多位填塞到同一表面。但驅動器的機械方面與尋道相關(傳動手臂速度和旋轉速度),改善相當緩慢
[2]
。因此,為了攤銷 I/O 成本,
必須在尋道之間傳輸儘可能多的資料
。
作業系統中的硬碟
就像程序是 CPU 的抽象、地址空間是記憶體的抽象一樣,儲存在作業系統的抽象是檔案(目錄也是一種檔案)。
如果算上核心中的檔案系統、驅動等,Linux 的儲存架構大體如下:

一個具體的讀流程
[3]
:
系統呼叫
read()
會觸發相應的 VFS(Virtual Filesystem Switch)函式,傳遞引數有檔案描述符和檔案偏移量;
VFS 確定請求的資料是否已經在記憶體快取中;若資料不在記憶體中,核心需要透過塊裝置層從物理裝置上讀取資料;
透過通用塊裝置層(Generic Block Layer)在塊裝置上執行讀操作,啟動I/O 操作,傳輸請求的資料;
在通用塊裝置層之下是 I/O 排程(I/O Scheduler),根據核心的排程策略,將對應的 I/O 插入佇列;
最後,塊裝置驅動(Block Device Driver)透過向磁碟控制器傳送相應的命令,執行真正的資料傳輸;
我們從上到下來看一些關鍵的點。
VFS(Virtual File Systems)

VFS 為多種不同的檔案系統提供一個通用的介面,通常包含四個部分:
Superblock:包含關於特定檔案系統的資訊,例如檔案系統中有多少個 Inode 和資料塊、Inode 表的開始位置等等;
Inode(Index node):描述檔案的元資料的結構,包括:檔案型別(例如,常規檔案、目錄等)、大小、許可權、一些時間資訊、分配給它的塊數,以及有關其資料塊駐留在磁碟上的位置的資訊;
Dentry(Directory Entries):目錄。VFS 是以完整的路徑名作為引數,需要遍歷路徑的目錄讀取 Inode 資訊,一般放到記憶體中;
File:程序開啟的檔案;
這裡我們不討論這些資料結構是如何具體實現的,我們重點關注作業系統如何對讀寫 I/O 進行最佳化的,這些最佳化常常啟發人們後續的軟體設計。
Page Cache
Linux 2。2版本之前核心同時有
Page Cache
和
Buffer Cache
兩個 cache,到了 2。4 版本後這兩個 cache 被合在了一起,現在核心只有
Page Cache
[4]
倘若沒有任何快取的情況下:
對於開啟檔案,每次都需要對目錄層次結構中的每個級別至少進行兩次讀取(一次讀取相關目錄的 inode,並且至少有一次讀取其資料)。
我們要建立一個新的檔案,至少需的 I/O 有:一次查詢空閒的 inode,一次寫入 inode 的儲存(將其標記為已分配),一次寫入新的 inode 本身(初始化它),一次寫入目錄的資料,一次讀寫目錄的 inode 以便更新它,最後一次寫入真正的資料塊——
所有這些只是為了建立一個檔案!
[5]
Page Cache 位於 VFS 和檔案系統之間
[6]
,在記憶體中儲存常用的塊,如果所需的頁面已經存在,則根本不需要呼叫檔案系統程式碼。第一次開啟可能會產生很多 I/O 來讀取目錄的 inode 和資料,但是根據區域性性原理,大部分時候會命中快取。
如果寫入資料,則首先將其寫入 Page Cache,然後作為髒頁(dirty pages)進行管理,這些髒頁會定期(也會與系統呼叫
sync
或
fsync
一起)傳輸到儲存裝置。這裡也常被稱為寫緩衝(write buffering),主要有以下三個好處:
透過延遲寫入,將許多小的 I/O 成批寫入到磁碟;
透過將一些寫入快取在記憶體中,系統可以排程後續的 I/O,從而提高效能;
一些寫入可以透過拖延來完全避免。例如,如果應用程式建立檔案並將其刪除,則可以透過延遲寫入完全避免寫入磁碟。
有些系統(如資料庫)不喜歡這種折中,因此,為了避免由於寫入緩衝導致的意外資料丟失,它們就強制寫入磁碟,透過呼叫
fsync()
,使用繞過快取的直接 I/O(direct I/O) 介面,或者使用原始磁碟(raw disk)介面完全避免使用檔案系統。
通用塊層(Generic Block layer)

對於 VFS 來說,塊(block)是基本的資料傳輸單元;但對於塊裝置(硬碟也是塊裝置中的一種)來說,扇區是最小定址單元,塊裝置無法對比扇區還小的單元進行定址和操作。通用塊裝置層(Generic Block Layer)就是這一轉換的中間層,也是核心的一個組成部分,它處理系統所有對塊裝置的請求。有通用塊裝置層後,核心可以方便地:
為所有的塊裝置管理提供一個抽象檢視,隱藏硬體塊裝置的差異性;
提供不同的 I/O 排程策略,能夠最佳化效能,減少磁頭移動次數,減少磁碟擦寫次數,延長磁碟壽命;
扇區大小是裝置的物理屬性,一般大小是 512 位元組。由於扇區是塊裝置的最小可定址單元,所以塊不能比扇區還小,只能整數倍於扇區大小,一般是 4K。
但是,在更新磁碟時,驅動器製造商唯一保證的是單個 512 位元組的寫入是原子的(具體情況參見製造商說明書)。因此,如果發生不合時宜的掉電,則可能只完成部分寫入。
塊裝置驅動層(Block Device Driver)
I/O 排程後的請求會交給相應的裝置驅動程式去進行讀寫,驅動層中的驅動程式對應具體的物理儲存裝置,向控制器發出具體的指令來讀寫資料。由於不是做驅動開發,這裡不是我們關注的重點。
常見的硬碟 I/O 最佳化
透過上面的分析,我們知道 Linux 一次讀寫請求到達磁碟的過程,為了降低檔案系統的 I/O 成本,Linux 主要:
透過快取來提高讀寫效能,本質就是減少磁碟尋道次數;
同時根據磁碟順序讀寫快、隨機讀寫慢的特點,儘量做追加寫;
這些設計思想也被許多開源軟體廣泛採用。
追加寫
Google BigTable
[7]
的論文把 LSM-Tree(Log Structured-Merge Tree)
[8]
這個古老的資料結構帶回前沿,基於 LSM-Tree 的儲存引擎有:Leveldb、Rocksdb、HBase、Cassandra 等等。不同於傳統的 B 樹類儲存引擎,基於 LSM-Tree 的儲存引擎尤其適合寫多讀少的場景。
當一個寫請求到達時,它會被寫到 memtable 中,memtable 在記憶體裡維護一個平衡二叉樹或者跳錶來保持 key 有序(memtable 同時會寫 WAL 來備份資料到磁碟,以便崩潰恢復),當 memtable 達到既定規模時,就會轉換為 immutable memtable(不可變 memtable,顧名思義,只讀的),然後後臺程序會將 immutable memtable 壓縮成 SSTable(Sorted String Table,即有序的) 寫到磁碟。

儲存引擎只做了順序磁碟讀寫,因為沒有檔案被編輯,增加、修改或刪除操作都用簡單的生成新的檔案來儲存。舊的檔案不會被更新,重複的記錄只會透過建立新的紀錄來覆蓋,這當然也就產生了一些冗餘的資料。顯然隨著資料的不斷修改,SSTable 的檔案數量會不斷的增加,
所以,系統會定期的執行合併(compaction)操作,即把多個 SSTable 歸併為一個大的 SSTable,移除重複的更新或者刪除紀錄,同時也會刪除上述的冗餘。透過這樣的方式減少了檔案個數的增長,保證讀操作的效能。因為 SSTable 檔案都是有序結構的,所以合併操作也是非常高效的。
當然 LSM-Tree 實現還有很多具體的細節,例如:快照、SSTable 索引、如何組織合併後的 SSTable 等內容,這裡我們暫且不表,後面我們會專注於分析 LSM-Tree 的具體實現(leveldb、rocksdb)。
總之,LSM-Tree 充分利用了
記憶體隨機讀寫 + 順序落盤 + 定期歸併
來獲取最大效能。
較大的檔案
硬碟最適合順序的大檔案 I/O 讀寫,在硬碟上分散的多個小檔案會損害效能;同時,元資料過多也會帶來很多 I/O 開銷(請求很多次 inode)影響效能,所以我們儘量:
將小檔案合併為大檔案
最佳化元資料儲存和管理
Google File System
[9]
和 Facebook Haystack
[10]
是兩個典型的案例:
GFS 選擇了當時看來相當大的 64M 作為資料儲存的基本單位,就是為了減少大量元資料;
Facebook Haystack 同樣將小檔案集合成大檔案來減少了元資料數目;同時精簡元資料,去掉一切 Facebook 場景中不需要的元資料,壓縮元資訊到足夠小並全部載入到記憶體中,避免請求 inode 帶來的開銷。
碼字不易,歡迎關注我的公眾號:

參考
^https://en。wikipedia。org/wiki/Disk_storage
^
“Hardware Technology Trends and Database Opportunities” David A。PattersonKeynote Lecture at the ACM SIGMOD Conference (SIGMOD ’98) June, 1998
https://people。eecs。berkeley。edu/~pattrsn/talks/sigmod98-keynote-color。pdf
^https://www。ilinuxkernel。com/files/Linux。Generic。Block。Layer。pdf
^https://books。google。de/books?id=lZpW6xmXrzoC&pg=PA348&dq=linux+buffer+cache+page+cache&cd=1#v=onepage&q=linux%20buffer%20cache%20page%20cache&f=false
^
“Operating Systems: Three Easy Pieces” Peter Reiher
http://pages。cs。wisc。edu/~remzi/OSTEP/file-implementation。pdf
^
“The future of the page cache”
https://lwn。net/Articles/712467/
^
“Bigtable:A distributed storage system for structured data” Chang F;Dean J;Ghemawat S;Hsieh WC,Wallach DA,Burrows M,Chandra T,Fikes A,Gruber RE, 2006
https://static。googleusercontent。com/media/research。google。com/zh-CN//archive/bigtable-osdi06。pdf
^
Patrick O‘Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil, The Log-Structured Merge-Tree。 Acta Informatica 33, June 1996。
https://www。cs。umb。edu/~poneil/lsmtree。pdf
^
Ghemawat, S。, Gobioff, H。, and Leung, S。-T。 2003。 The Google file system In 19th Symposium on Operating Systems Principles。 Lake George, NY。 29-43。
https://static。googleusercontent。com/media/research。google。com/zh-CN//archive/gfs-sosp2003。pdf
^
Beaver D, Kumar S, Li HC, Sobel J, Vajgel P et al (2010) Finding a needle in haystack: facebook’s photo storage。 In OSDI, vol 10。 pp 1–8
https://www。usenix。org/legacy/event/osdi10/tech/full_papers/Beaver。pdf