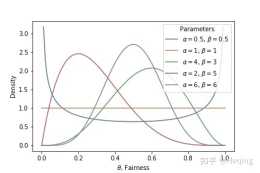
圖[2]: 基於Beta分佈的貝葉斯更新演算法可以看出,按照貝葉斯學派的思路,假如繼續進行兩次拋硬幣實驗,且兩次結果都為,那麼硬幣偏向的機率就增大了,圖中的pdf也是機率集中在的情況
那麼現在我們就可以得到煙霧報警器響的時候發生火災的機率現在大家應該能體會到貝葉斯公式的意義,即在很多時候,對於我們想要求的並不是直接能得到的,例如在目標追蹤領域,我們通常是先得到了測量結果,再反過來推算目標的真實位置
( σ‘ω’)σ):用某種分佈的密度函式算出訓練集中各個樣本連續型特徵相應維度的密度之後,根據這些密度的情況將該維度離散化、最後再訓練離散型樸素貝葉斯模型直接結合離散型樸素貝葉斯和連續型樸素貝葉斯——亦即將離散維度的條件機率和連續維度的機率

貝葉斯理論的精粹就在於,它完全而且完美的運用了你對一個理論的信念(prior belief)和你收集的資料(data或likelihood),從中得出結論(posterior belief),告訴你這個理論存在的機率或者這個理論模型引數的分

交叉熵、均方差損失函式,加正則項的損失函式,線性迴歸、嶺迴歸、LASSO迴歸等迴歸問題,邏輯迴歸,感知機等分類問題、經驗風險、結構風險,極大似然估計、拉普拉斯平滑估計、最大後驗機率估計、貝葉斯估計,貝葉斯公式,頻率學派、貝葉斯學派,機率、統
3)你現在掌握了的資訊,是這件事不會發生的一個噪聲的機率有多大

5. 粒子濾波(Particle Filter)此時對權重更新公式進行變形(在不產生歧義情況下部分內容用點省略):6. 總結本文首先從濾波問題說起,指出了貝葉斯濾波框架下積分很難求的問題
工作原理:和許多在 Facebook 和 Instagram 上使用的推薦系統一樣,Facebook News Feed 使用各種方法(比如機器學習模型預測)對內容進行排序,這些方法透過一系列規則組合起來形成一個配置策略
略去對於所有的類別相同的,樸素貝葉斯分類器表達為:令表示訓練集中第類樣本組成的集合,若有充足的獨立同分布樣本,則可容易地估計出類先驗機率:對離散屬性而言,令表示中在第個屬性上取值為的樣本組成的集合,則條件機率可估計為對連續屬性,可考慮機率密

3節 貝葉斯估計”,例如若資料集總不存在y=1的標記,也就是說#手寫資料集中沒有1這張圖,那麼如果不加1,由於沒有y=1,所以分子就會變成0,那麼在最後求後驗機率時這一項就變成了0,再#和條件機率乘,結果同樣為0,不允許存在這種情況,所以分
根據邊緣機率和聯合機率密度的定義,是對所有可能的的積分,即又根據條件獨立性有因此可以得到預測的分佈由於根據模型本身有,根據貝葉斯定律,有(其中和前面已有推導),則代入計算(比較複雜沒有推),有期望值仍然是MAP估計的值,但是現在可以得到方差

認知心理學和行為經濟學關於理性偏見的介紹正是這樣,很多人也人云亦云地告訴你如何糾正你的認知偏差

將剛剛的公示進行進一步泛化,我們就可以得到貝葉斯定律的公式: 為什麼貝葉斯定律很重要在公式中,右邊的條件機率部分也成為我們的似然引數(likelihood),也稱為(這句話我覺得翻譯了就很乖,所以不翻譯了) the likelihood o
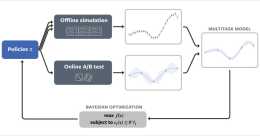
淺談貝葉斯最佳化這裡先介紹一下貝葉斯最佳化 (BO),這裡舉一個簡單的例子,比如我們想要找未知函式的最大值,於是我們基於已經觀測了的函式值對進行建模,然後根據訓練的模型找到最可能是最大值點的然後進行取樣,接著將得到的新的樣本點加入已觀測資料
2 貝葉斯估計貝葉斯方法提供了一種根據觀察到的資料對之引數的機率分佈進行更新的方法

顯著性檢驗要“僵硬地”設定一個小機率事件,而貝葉斯估計能夠直接給出引數的機率分佈,零假設在機率分佈中的位置一目瞭然

μ, σ) 它的意思是「在模型引數μ、σ條件下,觀察到資料 data 的機率」

2.貝葉斯決策理論(Bayesian Decision Theory,BDT)1.基於最小錯誤率的Bayes決策a.條件錯誤率P(e|x)b.每個決策的錯誤率c.整個過程最小決策的錯誤率,需要正確分配的機率maxd.利用Bayes公式2.基
如果表示訓練集中第類樣本組成的集合,那麼可容易的估計出類先驗機率:類先驗機率能夠簡單求解,下面是類條件機率:針對離散屬性而言,令表示在中第個屬性取值為的樣本組成的集合,那麼類條件機率為:針對連續屬性而言,可考慮機率密度函式,假定,其中分別是
例子2:還是相同的小劉喜歡女神的背景,不過這次小劉要根據女神是不是喜歡他來進行是否向女神表白,因為將女神不喜歡小劉判斷為喜歡小劉的風險較大,所以這裡我們將權重設定為:我們知道貝葉斯後驗機率為:加入代價後的貝葉斯風險為:,仍舊判別問女神喜歡小