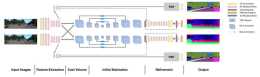
Glyce: 基於中文字形的NLP模型
香儂科技釋出基於中文字形的深度學習模型 Glyce
文章連結:
概述
漢字是古老的象形文字(logographic language),歷經幾千年的歷史演變,是當今世界上依然被使用的最古老的文字。漢字與英文有著本質區別:大多數漢字的起源於圖形,所以漢字的字形中蘊藏著豐富的語音資訊。即便是不識字的人,有時候也可以猜到一個漢字的大概意思。相反,英文很難從字形中猜出語義,因為英文是 alphabetic language,所基於的羅馬字母反映更多的是一個詞的讀音,而並不是語義。

圖1:中文是象形文字,很多字元經過漫長的歷史演變從圖畫逐漸變成如今的文字
然而當今中文自然語言處理的方法,大多是基於英文NLP的處理流程:以詞或者字的ID為基準,每一個詞或者字有一個對應的向量,並沒有考慮漢語字形的資訊。Glyce提出了基於中文字形的語義表示:把漢字當成一個圖片,然後用卷積神經網路學習出語義,這樣便可以充分利用漢字中的圖形資訊,增強了深度學習向量的語意表達能力。Glyce在總共13項、近乎所有中文自然語言處理任務上重新整理了歷史記錄。
基於字形的語義表示
現在在英文embedding上的研究大都基於word、sub-word及character級別的語義嵌入表示,而在中文上,我們一般停留在word(詞)或character(字)級。但注意到這裡的character更像是對應到英文中的sub-word級別,例如詞根和詞綴。所以,我們能不能再將中文的“字”切分為更小的單位,從而我們能夠從這種單位中學習到更底層的語義相關性呢?一個直觀的想法是,我們可以利用漢字的字形特點。
漢字是一種象形文字,在發展的過程中產生了形聲、象形等六種構字法,但無論是哪一種構字法,我們都可以從它們的字形中“推測”一個我們不認識的字的含義。顯然,漢語字形的資訊應該有助於語義建模。但是,我們很難將一個個字再切分為更細的字元編號表示,也就沒有辦法像“字”或者“詞”那樣去構造字典進行直接的語義嵌入,所以,我們自然就想到用基於影象的方法去提取漢字的語義特徵。
最近也有一些研究注意到了這些事實(Liu et al。, 2017; Zhang and LeCun, 2017)。但是令人遺憾的是,他們的研究沒有表現出持續的效能提升,一些研究甚至得出了負面效果(Dai and Cai, 2017),字形的加入實際上降低了效能。(Liu et al。, 2017; Zhang and LeCun, 2017)在文字分類任務上利用相似的策略測試了這一思路,結果模型效能只在非常有限的幾種情況下有所提升。
那麼這樣一種“反直覺”的實驗結果是否真的說明漢字的字形資訊無益甚至有損於下游任務的語義捕捉和語言建模呢?我們認為,之前的研究至少存在以下不足:
沒能從歷時的角度考察漢字字形的關係。漢字實際上是經過了漫長的演變,發展到今天,已經是作了非常大的簡化。而過去的研究只是從簡體字或繁體字的字形影象上去提取漢字語義表示,這是十分侷限的。
未能使用合適的CNN結構。與大小為800*600的ImageNet影象不同,漢字影象的大小要小得多(通常是12*12)。這就需要不同的CNN架構來捕捉字元影象的區域性圖資訊。
未能使用合適的調節函式。與包含數千萬資料點的ImageNet影象分類任務不同,漢字僅有約一萬個。因此輔助訓練目標對防止過擬合、提升模型泛化能力非常關鍵。

表1:漢字的歷史演變程序
針對以上問題,我們提出了Glyce,一種漢字字形的表徵向量。我們仍然將漢字當作影象,並使用CNN來獲取語義表徵,但是試圖用以下方法來解決上述三個問題:
使用歷時的漢字字形(如金文、隸書、篆書等)和不同的書寫風格(如行書、草書等)來豐富字元影象的象形資訊,從而更全面地捕捉漢字的語義特徵。
提出Tianzige-CNN(田字格)架構,專門為中文象形字元建模而設計。
新增影象分類的輔助損失,透過多工學習增強模型的泛化能力。
下面我們來具體介紹這三個設計。
Glyce: 基於中文字形的NLP模型
使用歷史漢字
正如我們提到的,我們首先使用了不同歷史時期的中文字元:如今廣泛使用的簡體中文字元是經過漫長的歷史演變而來的。簡體中文書寫更加方便,但是同時也丟失了大量的原始圖形資訊。Glyce提出需要運用不同歷史時期的中文字元,從周商時期的金文,漢代的隸書,魏晉時期的篆書,南北朝時期的魏碑,以及繁體、簡體中文。這些不同類別的字元在語義上更全面涵蓋了語義資訊。(表1)
使用Tianzige(田字格)-CNN架構
標準的CNN結構接受一個

的輸入,然後使用

的卷積核和max-pooling去提取特徵。然而,直接使用這樣的Deep CNN結構會導致“逆改善”,因為:
漢字影象的尺寸一般很小。比如ImageNet的影象都是800*600,而中文漢字的尺寸往往只需要用一個12*12的灰度圖便可以表示。尺寸上的巨大差異並不能使傳統的CNN結構通用。
訓練資料大小的限制。ImageNet有巨大的訓練集,而漢字卻只有大概一萬個。

圖2:漢字的田字格與對應的Tianzige-CNN結構
為此,我們提出了Tianzige-CNN結構。Tianzige(田字格)是中文傳統的書寫方式,它由2*2的小正方形組成(見圖2左)。田字格結構反映了中文偏旁部首的排列組合順序,所以非常適合中文字形資訊提取。
現在給定輸入

,首先用一個大小為5的卷積核去做卷積,得到一個1024通道的輸出,然後用大小為4的max-pooling將8*8的特徵圖降為2*2的Tianzige尺寸。現在,這個2*2的Tianzige結構表示了漢字的字形特徵。最後,我們用group convolution(Krizhevsky et al。 2017; Zhang et al。 2017)得到漢字的字形表徵向量。(見圖2右)
顯然,我們還可以加入上述提到的多種字型,也即將輸入的2D圖

換成一個3D圖

,這裡的

就是我們想要輸入的字型數量,

是影象大小。
加入影象分類損失函式
為了進一步減少過擬合,我們使用了影象分類作為附加的損失函式。漢字影象
透過Tianzige-CNN得到的漢字字形特徵向量

直接被送去預測它是哪個漢字。假定
對應的漢字標籤是

,那麼影象分類的損失函式為:

讓

為下游任務的損失,那麼總的損失為:

其中,

。這裡

是當前的epoch,
![\lambda_0\in[0,1]](https://img.heatask.com/upload/website_attach/8LbArDoLqCKNkFpAV=-+UEezKGvh3mRdMwQApK7ABHP_VgDPte_0T6FZ69jM4DildGiyGcS_rEhkOUiPtek2w.jpeg)
是初始值,
![\lambda_1\in[0,1]](https://img.heatask.com/upload/website_attach/NW2WGgB5NG-YhdmaBULQmznRFzXTCcFnyl7WMMFibe1+inOfn3oeLLz+AN83Nu=P4ZJc4oqkO95rvG-fn3H+M.jpeg)
是每次的衰減率。這個式子表明影象分類損失的影響會隨著訓練次數的增大而減少。

圖3:Glyce模型結構總覽
字嵌入與詞嵌入
為了將字形資訊和傳統的詞向量和字向量結合起來,我們針對詞級別的任務和字級別的任務,提出了兩種Glyce模型結構。模型的結構總覽見(圖3)。
在字級別的任務中,可以首先透過上述方法得到一個Glyph Embedding,然後和對應的Char Embedding結合起來,具體可以使用concat,highway或者全連線,然後送入下游任務。
在詞級別的任務中,我們首先有一個Word Embedding,對這個詞而言,分別對其中的每一個字進行字級別的embedding操作,把所有的字級別的embedding用max-pooling結合起來,然後再和這個Word Embedding結合,送入下游任務。
實驗結果
我們在語言建模、NER、MT等13個任務上進行了實驗,並與其他模型進行了對比。下面我們重點分析幾個任務的結果。
我們首先在字級和詞級的語言建模上進行了實驗。資料集使用了CTB6,採用標準的LSTM結構。實驗結果見(表2)。

表2:Glyce在字級(左)與詞級(右)語言建模上的表現
從上述兩個任務的實驗中我們可以看到,只用漢字字形影象(glyph)比只用字(charID)或只用詞(wordID)要好,這驗證了中文漢字的字形特徵的確可以透過合理的模型結構來獲得更好的語義資訊。在詞級任務上,我們發現,無論是charID還是wordID,它們都能透過附加glyph達到更好的效果,特別地,使用wordID+glyph到達了詞級的最好效果。我們認為,這可能是因為相比charID,glyph已經能夠提供足夠好的語義資訊,而再加上charID反而使這種資訊更加混亂。
另外,(表2左)也展示了附加影象分類損失的作用。我們發現,使用影象分類比不使用影象分類損失效果普遍更好,特別是在字型多達8的時候。如果此時沒有附加的影象分類作為學習目標,各種各樣的字型資訊就會混雜在一起,從而誤導模型的學習方向,極大降低學習效果。在字級任務上,我們使用charID+glyph+8 scripts+影象分類損失達到了最好。
然後我們在命名實體識別(Named Entity Recognition)、中文分詞(Word Segmentation)和詞性標註(Part of Speech Tagging)上進行了實驗。實驗結果見(表3)。

表3:Glyce在NER(左)、中文分詞(右上)和中文詞性標註(右下)上的表現
接著,我們又在依存句法分析(Dependency Parsing)、語義角色標註(Semantic Role Labeling)、句子語義相似匹配(Sentence Semantic Similarity)、意圖識別(Intention Identification)、中英翻譯(Chinese-English Machine Translation)、情感分析(Sentiment Analysis)、文件分類(Document Classification)、語篇分析(Discourse Parsing)等任務上進行了實驗,實驗結果見(表4,表5,表6),詳細實驗過程詳見論文。

表4:Glyce在依存句法分析(左上)、SRL(左下)、句子語義相似匹配(右上)和意圖識別(右下)和一些模型的對比及表現

表5:Glyce在中英機器翻譯(左)和情感分析(右)中的表現

表6:Glyce在文件分類(左)和語篇分析(右)中的表現
結語
我們提出了一種基於中文字形表示的語義模型,針對中文特殊的字形結構設計了Tianzige-CNN結構來捕捉字級語義,並且使用不同歷史時期的漢字來增強這種能力,加入了影象分類任務更好地進行泛化。實驗表明我們提出的Glyce模型能夠更好地構建中文字級、詞級的語義表示,在多項任務中實現SOTA。
我們希望本文能為以中文為代表的象形文字在構建更好的語義表示上的研究提供一些啟發。
文章作者:Glyce作者數量多達九個。 Yuxian Meng(孟昱先)與Wei Wu(吳煒)與並列為第一作者。Wei Wu(吳煒)在字元級語言模型任務上設計並實現了第一個Glyce-char模型。Yuxian Meng(孟昱先)提出了Tianzige- CNN結構,影象分類作為輔助目標函式和衰變λ。Jiwei Li(李紀為)提出使用不同歷史時期的中文字元。Yuxian Meng(孟昱先)負責詞級語言模型和意圖分類的結果; Wei Wu(吳煒)負責中文分詞,命名實體識別和詞性標註的結果。Qinghong Han(韓慶宏)負責語義角色標註的結果;Xiaoya LI(李曉雅)負責中文-英文機器翻譯的結果; Muiry Li(李慕宇)負責句法依存分析和詞性標註的結果;Mei Jie(梅傑)負責篇章分析的結果;Nie Ping(聶平)負責語義相似度的結果; Xiaofei Sun(孫曉飛)負責文字分類和情感分析的結果。Jiwei Li(李紀為)為Glyce通訊作者