Blind Image Super-Resolution via Contrastive Representation Learning閱讀筆記
這是一篇發表在NIPS2021上的論文,主要內容是利用對比學習來解決盲超解析度問題,CVPR21上有一篇工作利用對比學習來學習退化表徵(DASR),這篇就提出了它的一些問題:
Background
過去的方法大都假設同一張影象中的退化核是恆定的(可能退化核很複雜,但是在同一張影象上不變),並以此為基礎展開工作。然而當遇到更加複雜的情況時,如一張影象中的退化方式隨空間發生變化時,這些方法明顯會無法適應,所以這篇文章就旨在提出一種解決空間變異退化的盲超解析度方法。
Method
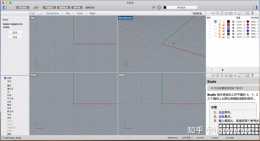
為了解決上述問題,作者提出了了如下圖所示的網路框架CRL-SR,主要由CDE(Contrastive Decoupling Encoding)和CFR(Contrastive Feature Refinement)兩個部分組成。我的理解是,CDE是學習提取解析度不變特徵(即乾淨的低頻特徵),丟掉解析度變化的特徵,因為在這裡麵包含了複雜的退化,這種退化可能是隨空間變化的。這樣無論影象中的退化如何變化都不會影響最終提取的特徵。CFR則是從上一步提取到的乾淨的低頻特徵中恢復高頻資訊。

個人感覺這個圖化的真不錯
CDE
CDE結構很簡單就是一個雙流的特徵提取器(注意這兩個Encoder是不同的,不共享引數),透過雙向對比損失讓兩個Encoder提取的特徵

和

之間的互資訊最大化。雙向對比損失包含兩個部分

和

,這兩部分的公式是一致的,第一個是以LR影象提取的特徵做anchor,第二個是以HR影象提取的特徵做anchor(可能因為這個所以稱之為雙向),公式如下(就是NCE loss):

和
分別包含m個特徵向量(我的理解是從同一張圖片中隨機分割的m個patch提取的特徵),對於
,
中的每個特徵向量分別作為anchor,剩下的m-1個向量做負樣本,
的m個特徵向量做正樣本。作者這樣做是因為相比來自其他影象的特徵相比它們更難與anchor區分(不同影象做負樣本的話太簡單了可能起不到效果)。這樣做能讓來自LR和HR的特徵投影到同一特徵空間中(乾淨低頻),仔細想想這個雙向的loss還是巧妙中帶著一點玄學。
注意在計算loss之前先要透過兩層MLP將所有特徵向量對映到更高維空間中的S維特徵向量,這是參考SimCLR的做法。
CFR
由於上一步提取的解析度不變特徵包含的相關資訊很少,因此直接生成丟失的高頻細節是具有挑戰性的。CFR主要包含幾個部分:

從LR影象中提取的特徵恢復高解析度圖片,

從HR影象中提取的特徵恢復高解析度圖片,共享引數的Encoder

。
這一部分的主要貢獻是提出了一種新的條件對比損失。主要的思想是在拉近anchor和positive sample的同時使其原離conditions。(這裡我不太理解,InfoNCE沒有這樣的效果嗎)

(b)是作者的思想,(c)是常規的方法
因為每個樣本丟失的高頻細節是不同的,對每個樣本在計算loss時加入了一個懲罰因子:

最終loss如圖所示:

同時為了確保HR影象的特徵

中包含足夠的高頻資訊,還加入了從
恢復的HR影象和GT之間的loss:

就是常見的L1 loss
最後總的loss是三者求和。這一部分我感覺和前一篇UDA超分裡的一些思想很相似,

的目的是將

h和
投影到同一特徵空間S中,同時
和重構損失讓特徵
保留高頻資訊,這樣就能讓S向高畫質影象的特徵空間靠近。(簡單說就是SR和HR的特徵相互靠近,HR特徵儘量保持不變,那不就能讓SR向HR優化了)
Experiment
在竄在空間編譯退化的情況下的實驗結果,這個提升還是非常可觀的:

指標是PSNR

消融實驗:

還有一些實驗這裡就不在贅述了,本人學識有限,有理解錯誤的地方還請大家指正。